In 2025, Sundar Pichai admitted that over 25% of Google's new code was written by AI. The CEO of Robinhood also made a similar announcement about his company. The term "vibe coding" entered the mainstream lexicon to refer to the practice of allowing AI coding assistants to generate entire programs from natural-language inputs. Meanwhile, in computer science departments across the world, professors were also noticing that MOSS, the plagiarism checker invented at Stanford back in 1994 and still the dominant solution for code similarity checking, was failing to detect AI-generated homework at a rate that left teachers with few options.
The problem of AI detection in written text has received enormous attention. The AI detection problem in code has not received the same attention, even though it is more difficult, and the stakes for students caught in the middle are just as high. Essay-based text detectors do not work well for source code because of the differing syntactic rules and stylistic and statistical norms. MOSS detects students who plagiarize each other's code, but it fails to detect students who have developed functionally unique AI-generated code because such code lacks the token-similarity signature of human-written code. The problem of beginner code is two-sided. Inexperienced programmers produce code that is repetitive, formulaic, and simplistic, as the AI detection community associates with machine-written code.
This article will describe the unique differences between code and text for detection purposes, the failure of old methods in the AI world, new research on code detection, and the false positives that students encounter when writing legitimate beginner code that happens to look like AI code. An AI text humanizer addresses the statistical profile of written text, not code, but understanding why code differs helps writers and researchers grasp the full scope of the AI detection problem in academic settings.
Key Takeaways
Code detection is a completely different task compared to text detection. Text detectors calculate perplexity, burstiness, and stylometry of the detected text. However, code has its own statistical properties, syntactic restrictions, and functional needs, and natural language detection is not applicable to source code.
AI code detection accuracy: As discussed in "From Pangram," text-trained AI detectors can identify a large percentage of AI-generated code but also show a high number of false negatives, and MOSS, the standard code similarity tool, detects peer collusion well but fails to detect AI submissions because each time an AI program is run, a new and functionally distinct solution is created with different structural patterns.
False positives are higher for beginner programming students. In addition, beginner-level code for problems such as sorting algorithms, linked list implementations, and string manipulation typically yields only a limited number of correct solutions. Human code and AI-generated code for a beginner-level assignment are likely to look identical, not because of AI use but because there are a limited number of ways to write a correct bubble sort algorithm in Python.
A recent study published by AAAI in 2024 from Texas Tech University demonstrated that a CodeBERT-based approach achieved a high AUC (0.9) for detecting AI-generated code versus human code. However, the same study showed that even minor code changes, such as variable renaming and loop restructuring, significantly reduce code-detection accuracy, thereby enabling bypass vulnerabilities.
The use of GitHub Copilot and other AI coding assistants has also introduced a gray area in computer science education policies. "While it is functionally different from asking ChatGPT to write a solution and then copying it, it could also be considered a violation of a policy against AI use, and it is impossible to distinguish it from the previous case.
The most reliable method for computer science educators in 2026 is a multi-layered approach: MOSS for peer-based similarity, a code-specific AI detector for AI generation patterns, and oral verification for high-stakes tests. Tools designed to humanize AI-generated written content do not address code detection, which operates on entirely different signals.
Why Code Detection Is Harder Than Text Detection
If a text AI detector is run on a paragraph of text, it can calculate perplexity, check for burstiness, examine stylometric characteristics, and compare embedding distances against a distribution of human writing. If the same process is run on a Python function, however, most of the signals break down immediately.
Code Follows Syntactic Rules, Not Statistical Distributions
The freedom of expression in natural language is huge. There are thousands of ways to express the same idea, resulting in the unpredictability we see in lexical variety, which helps verify the presence of human authors. In contrast, source code lacks this freedom. Implementing a sorting algorithm in Python requires using the correct Python syntax. The correct implementation of a binary search tree has to exhibit certain structural characteristics, but these have no analog in natural language. The "low perplexity" we observe in AI-generated text, as measured by text detectors, is simply the appearance of well-written code, regardless of the author.
Functional Equivalence Produces Structural Convergence
For many programming problems, particularly at the introductory level, there are a limited number of correct solutions. If a student is asked to "implement merge sort in Java," a competent human student and a computer AI assistant would likely arrive at the same solution, with a similar recursive divide-and-conquer approach, similar variable names such as "left," "right," and "mid," and a similar merge step. A solution this similar is not the result of one copying the other, but rather of a limited number of correct solutions. A similar solution is marked by text detectors as AI-generated content. MOSS would flag this as peer collaboration. Neither is correct. Tools that bypass AI detectors through statistical adjustment work on natural language text, but code detection requires entirely different approaches because the convergence problem in code comes from the problem domain, not from language model behavior.
Training Data Dominance
The text AI detectors’ underlying models were likely trained on natural language text. The model’s learned probability distribution over text does not extend well to source code, as the structure of natural language and source code differ significantly. A model trained on essays will not know how to interpret consistent indentation, repetitive syntax, and predictable keyword usage in a Python script, or whether this is indicative of AI-generated code or simply good Python programming style. Code-based detection requires a model trained with code-based features and baselines.
MOSS and Traditional Code Similarity Tools in the AI Era
The Measure of Software Similarity (MOSS), developed in 1994 at Stanford University, has served as the basis for plagiarism detection in student code for the last three decades. This tool works by finding unusually high levels of structural similarity in the code. A student who plagiarizes another student's assignment and changes the variable names is likely to exhibit a high degree of structural similarity. A student who asks ChatGPT to write their assignment is likely to end up with something completely unlike any other assignment in the class.
MOSS software similarity. However, the tool itself states that it is not a plagiarism detection tool, but rather a similarity detection tool. This is important in the age of AI because AI-generated code differs from that produced by students in the class. Each time the student uses ChatGPT or GitHub Copilot to generate the code, the code is functionally unique. There is nothing for the tool to see.
Research Finding: HackerRank conducted internal research on MOSS performance in the AI era and found false-positive rates as high as 70 percent for simpler coding challenges, where independent students naturally produce structurally similar solutions. Simultaneously, MOSS missed AI-generated submissions entirely because ChatGPT produces novel code that does not match other submissions. When HackerRank researchers asked ChatGPT directly to help them evade MOSS detection in a second step, ChatGPT refused. On a third step, without explicitly asking for MOSS evasion, they obtained a stylistically varied solution that MOSS would not flag. The evasion required no code knowledge. |
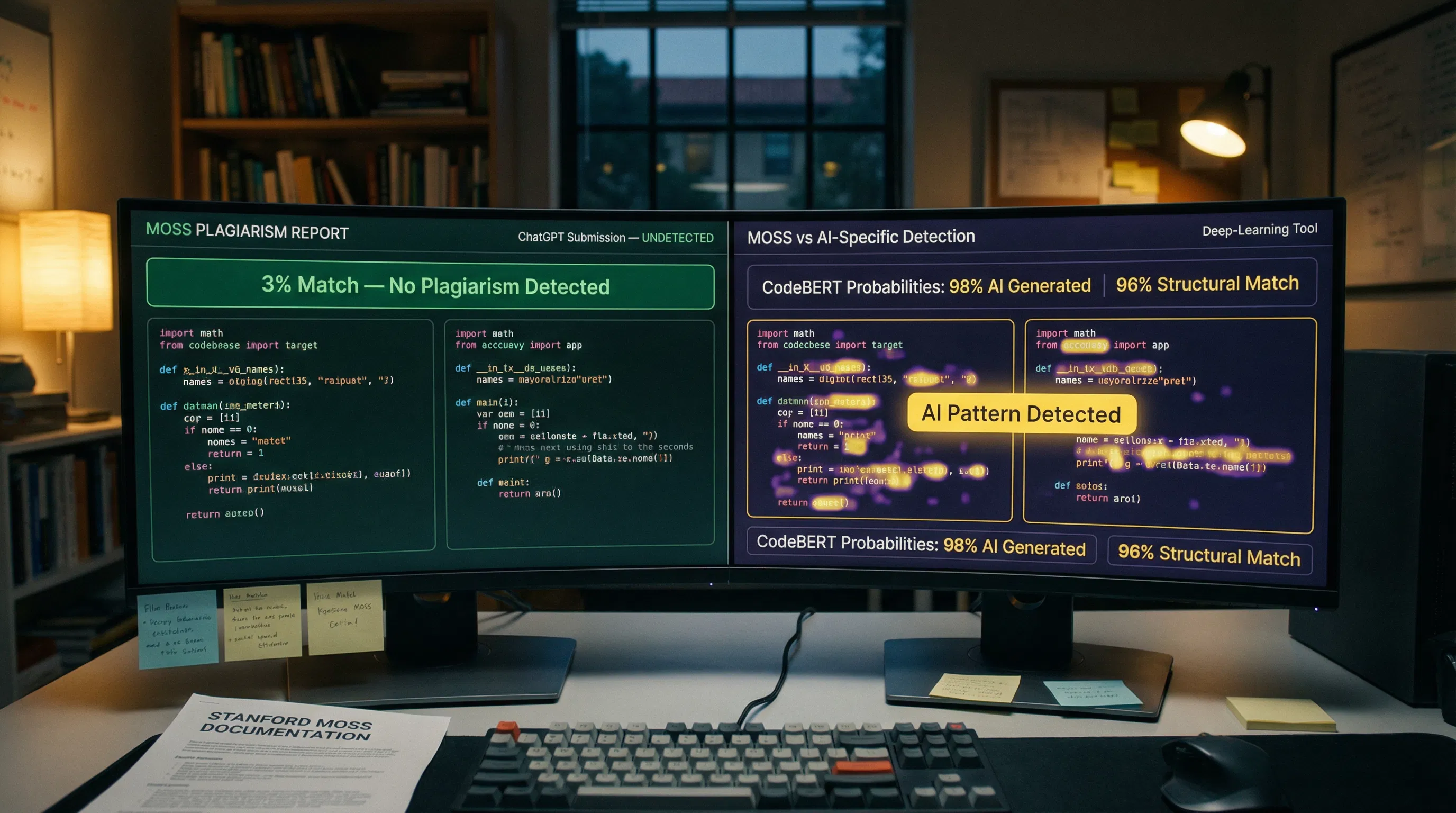
ChatGPT fools MOSS detection. This simply confirms the fundamental structural problem: MOSS is great at catching the kind of cheating it was designed to catch (direct copying with light modification) but has no ability to catch the kind of cheating it has enabled (functionally unique generation without similarity to any previous submissions). These are fundamentally opposing failure modes. The same tool produces false positives (misidentifying independent students who happen to solve the problem in similar ways) and false negatives (failing to detect AI-generated unique solutions), depending on the assignment. Using an AI humanizer tool to adjust text is an entirely different workflow; the relevant insight for CS educators is that MOSS needs to be supplemented with code-specific AI detection rather than replaced.
Can Text-Trained AI Detectors Work on Code?
The short answer is yes, to a degree, and not well enough to trust for enforcement. Text-based detectors such as GPTZero, Turnitin, and Originality.ai do detect AI-generated code to some degree, as it shares some statistical properties with AI-generated text. However, they have high false-negative rates for AI-generated code with varying styles and high false-positive rates for well-commented, beginner-written human code.
The Perplexity Approach for Code
AI code detection perplexity applied a perplexity-based approach using CodeBERT to detect code and discovered that the idea of "code naturalness" is related to the concept of "text naturalness" since AI-generated code is located at high-probability locations on the code distribution curve, and any change to it is more likely to increase the perplexity of the code. On the contrary, human-generated code has more variability. The research conducted at Texas Tech University, published at AAAI 2024, achieved an AUC above 0.9 for classifying AI-generated code from human-generated code. The main limitation of the above research is that bypass robustness was also considered for AI-generated code; i.e., small modifications, such as changing variable names or adding dummy operations, resulted in a significant decline in classification accuracy.
CodeBERT and Code-Specific Models
The most promising direction for code detection is to use models pre-trained on source code rather than natural language. CodeBERT, trained on code from GitHub repositories across multiple programming languages, produces code-appropriate contextual embeddings that capture programming language semantics rather than natural language semantics. A classifier fine-tuned on top of CodeBERT embeddings can learn stylometric differences between AI-generated and human-written code without relying on natural-language perplexity baselines that do not apply to syntax-constrained code.
The limitation is the training data. To fine-tune a CodeBERT classifier for a specific programming class, the instructor needs labeled examples of AI-generated student submissions for that class. Generalizing from the training data of one class to the assignments of another class is the same as the drop in accuracy for the task of text detection. A classifier for the programming language Python is not generalizable to Java. A classifier for an introductory programming class is not generalizable to advanced algorithmic programming. Tools that beat AI detectors for written text exploit similar cross-domain gaps; the structural parallel is that detection systems trained on specific distributions fail outside those distributions.
The Beginner Code False Positive Problem
The false positive risk in code detection may be most acute exactly where the stakes are highest: introductory computer science courses serving students with no prior programming experience. This is the group most likely to have genuine violations (they are the students whose AI coding tools help most directly), and it is also the group most likely to produce code that looks AI-generated even when it is entirely human-written.
A student in their first programming course implementing a linked list in Java will produce code that shares structural characteristics with other beginners' implementations and with ChatGPT's linked list code. The canonical structure of a linked list node class, the addFirst and addLast methods, the traverse loop, and the null checks are not stylistic choices; they are required. They are the functionally correct implementation of the data structure. A beginner has almost no latitude for creativity. The solution space for a correctly implemented linked list implementation is small enough that independent human solutions converge on patterns that AI code detectors associate with machine-generated code.
Core Problem: Introductory programming assignments present the worst-case scenario for code AI detection. The assignments have canonical solutions that all correct implementations share. Beginners have minimal room for stylistic individuality because they are following tutorial patterns, textbook examples, and course materials. AI assistants produce code from the same training data that informed those tutorials. The statistical profiles of beginner human code and AI-generated beginner code are closest precisely when students are newest to programming and most vulnerable to false accusations. |
Detecting AI-generated code published in Frontiers in Computer Science in 2025, it was confirmed that the current tools for detecting AI code, such as AI text detection tools including GPTZero, have difficulty distinguishing AI code from human code, and it was also confirmed that current plagiarism detection tools, such as MOSS, also have difficulty detecting AI code because the stochastic nature of the AI code generation does not have the deterministic similarity pattern that the MOSS tool was designed to look for. The authors also suggested using the pseudo-AI submission approach, in which baseline AI code is generated for each assignment.
For students in this situation, using reduced AI detection tools designed for written text does not address code false positives. The practical protections are the same as for any false accusation scenario: maintain a clear revision history of your code development, save intermediate versions showing debugging progress, document your reasoning in comments, and be prepared to explain your code's logic in an oral assessment.
GitHub Copilot and the Academic Integrity Policy Gap
GitHub Copilot suggests code completions as developers type. These are proposals for completing a line of code or an entire function. It is also free for use for any verified student through GitHub Education. According to a 2025 Stack Overflow developer survey, 84 percent of developers plan to use AI or already use it in their workflow. The idea that computer science students are not using Copilot is ridiculous.
It is possible that most computer science students who use Copilot are unaware of the line they cross between legitimate and illegitimate use. Copilot does not draw a line for the user; it simply makes suggestions. The line between legitimate and illegitimate use of Copilot is blurred for the user. The user who uses Copilot to write a line of code for a function they have written themselves is in a different category from the user who gets a solution for an entire assignment from ChatGPT; however, these two users are indistinguishable to code-detecting tools.
This creates a problem for institutions that are caught in a grey area. It's becoming harder to enforce a "no AI tools" policy across the board, especially when it disadvantages students who are using Copilot for legitimate productivity rather than cheating on assignments. It's also becoming harder to enforce a policy that allows Copilot for certain uses but prohibits it for others, without a way to detect how much of the work was suggested by Copilot versus how much was typed by a human. Using an AI content humanizer for written text comments and documentation in a coding submission is a separate question from the code itself; instructors evaluating both should use different tools and criteria.
Code Detection Tools: What Each Approach Can and Cannot Do
Detection Approach | What It Catches | What It Misses / False Positive Risk |
MOSS (Measure of Software Similarity) | Direct copying with variable renaming; peer collusion; similar structural patterns | AI-generated unique solutions; independent convergence on canonical implementations; high FP on simple assignments (up to 70% in HackerRank research) |
JPlag | Token-based code similarity; obfuscated copying; structurally similar submissions | AI-generated code that produces unique output; beginner solutions converging on standard patterns |
Text-trained AI detectors (GPTZero, Turnitin, Originality.ai) | Some AI-generated code that shares patterns with AI text; clearly formulaic code | False positives on beginner code; false negatives on stylistically varied AI code; not calibrated for code syntax |
CodeBERT-based code detection | AI-generated code with code-appropriate perplexity analysis; language-specific patterns | Requires code-specific training data; cross-language generalization gaps, and bypass via variable renaming and restructuring |
Pseudo-AI submission baseline (Frontiers 2025) | AI-generated code relative to assignment-specific baselines; more accurate than general models | Requires generating baseline AI code for each assignment; more labor-intensive than automated tools |
Behavioral + MOSS combined (HackerRank approach) | AI-generated code via behavioral signals: coding speed, submission patterns, error rates | Requires a proctored environment; not deployable for standard take-home assignments |
Oral / in-class verification | Definitive for any submission; catches both AI use and plagiarism regardless of the detection tool output | Labor-intensive; not scalable to large courses; less efficient than automated screening |
The takeaway here is that no single tool can detect all failure modes. In fact, for code-specific AI detection, you need a layered solution that includes MOSS for peer similarity, code-trained AI detection for AI patterns, and human verification. Tools designed to produce undetectable AI text do not cross over into the code domain. Written comments and documentation in a code submission may be evaluated with text detection; the source code itself requires code-specific methods.
False Positive Consequences for Students Writing Genuine Code
When a code detection tool flags a student's genuine work, the consequences in CS education can be severe and lasting.
Academic integrity proceedings. A flag from MOSS or a code detector, such as AI, usually triggers an official academic integrity proceeding in which the student is required to respond to the charge, attend meetings, and, in some cases, be given a grade penalty or fail the course, even if he or she is eventually cleared. The process is the penalty in many cases.
Grade penalties during investigation. Often, the assignment is put on hold while the case is being investigated. In the case of an assignment that contributes 20 percent to the total course grade, a temporary hold can affect the student's academic standing, especially towards the end of the semester.
Reputational impact in small programs. Computer science programs are small enough that being known as a student investigated for plagiarism, even without a finding of guilt, can affect peer relationships, research opportunities, and recommendations from faculty involved in the process.
Disproportionate impact on marginalized students. The same types of false positives we see in text detection (such as ESL writing, neurodivergent communication styles, and formal academic language) will also be present in code. Students who use extremely structured, tutorial-style code because they lack confidence in their programming will end up with code that looks more like AI, not less. Using a free AI humanizer for written assignments does not address this issue, but the equity concern applies equally to code-detection contexts.
What Computer Science Instructors Should Know
The first adjustment that CS teachers must make in 2026 is to recognize that MOSS alone is no longer a viable substitute for AI. It succeeds at catching what it was meant to catch (collusion among humans) but fails to catch what it was not meant to catch (AI-generated unique solutions). It has the wrong false positives (independent students on simple problems) and the wrong false negatives (AI-generated unique code).
Layer your detection. Use MOSS for peer-similarity screening and add a code-specific AI detector to detect AI-generated patterns. Treat both as screening tools that require human review, not as evidence. The creators of MOSS explicitly state that human judgment is required for every flag MOSS produces.
Require version history. The history of Git commits provides a clear record of code development over time. The student who has been developing his solution over time with incremental commits is vastly different from the student who submitted his solution in a single commit just 10 minutes before the deadline. One of the most effective and easiest ways to change is to require Git submissions with commit history.
Design assignments with individuality requirements. Assignments that are based on writing a comment explaining the student's specific reasoning, writing test cases that the student designed independently, or implementation aspects that the student must justify in writing are by far more difficult for AI to complete entirely than mere code submission. Also, they yield written artifacts that text detection can assess separately.
Use oral verification selectively. For the flagged ones, it's more informative to have a brief dialogue in which the student explains how their code works than to use a detection tool. The student who wrote their own code will almost always be able to explain it. A student who submits AI-generated code but does not understand it will almost never be able to understand it. AI detection bypass tools for text help writers protect genuine work from statistical misclassification; oral verification in code contexts serves the same protective function, giving genuine students a venue to demonstrate authentic understanding.
Be precise in your AI policy. A "no-AI" policy that fails to distinguish between Copilot for autocomplete, ChatGPT for debugging help, and an AI for a complete submission lumps these behaviors together, treating them as the same. It is impossible for students to adhere to a policy whose limits are not clear to them. Being clear on what is and is not allowed regarding AI assistance, and on how to cite it when allowed, helps prevent both occurrences.
What Students Coding Genuine Assignments Should Know
If you are writing your own code and worried about being falsely flagged, the most effective protections are process-based rather than tool-based.
Use Git from the start. Initialize a repository for every assignment, commit frequently, and write meaningful commit messages that document your thinking. A commit history showing incremental debugging progress, partial solutions that did not work, and gradual refinement is the clearest evidence of authentic development available. An AI-generated submission usually has no comparable history.
Comment your code as you go. Comments explaining why you made specific implementation choices, what you tried that did not work, and what you are still unsure about are authentically yours. AI-generated code typically has no comments. Your comments are your voice in the code and provide both evidence of authorship and a basis for oral verification.
Keep your development environment artifacts. Stack Overflow search histories, browser history showing documentation lookups, notes you took while working, and screenshots of error messages you debugged are all supplementary evidence that you wrote the code. None of it is necessary until it is, at which point having it is invaluable.
Know your institution's AI policy precisely. If your course allows Copilot for autocomplete but not for full solution generation, document where you accepted suggestions, and make sure you can explain every line of code regardless of its origin. If your course prohibits AI entirely, disable Copilot and do not use ChatGPT for coding help. Ambiguity about what you used puts you at a disadvantage if you are questioned. Tools designed to humanize AI writing for written text are separate from code tools; know which detection system applies to which part of your submission.
Solution Section: Building a Fair Code Detection Workflow
The ideal code detection workflow in 2026 balances enforcement effectiveness with fairness. No single automated tool achieves this. The answer is a layered, process-aware system that uses automation for screening, requires human judgment for decision-making, and designs assessments to enable verification.

Automated Screening Layer
Run MOSS for peer similarity on every submission. Add a code-specific AI detector, such as Codequiry or an institution-developed CodeBERT-based tool, calibrated on examples of AI-generated versus human-written code for the specific assignment. Use the combined output to identify the top five to ten percent of submissions that warrant closer review, not to make enforcement decisions directly.
Human Review Layer
Every flagged submission should receive a code review by an instructor or TA, along with the student's Git commit history. Reviewers should ask specifically: Does this student's commit history show incremental development? Are the comments in the student's voice or generic? Does the code style match what this student has produced in previous assessments? These questions can be answered without any detection tool.
Oral Verification for High-Stakes Cases
When automated screening and human review both raise concerns, a brief oral verification conversation resolves almost all genuine cases. A student who wrote their code can explain it. This scales poorly to entire classes but is appropriate for the small number of cases that survive the first two layers. Humanizing neurodivergent writing tools for written assignments helps students protect their genuine work from statistical misclassification; the equivalent in code is an oral verification conversation that gives genuine students the chance to demonstrate their understanding.
Assessment Design as a Prevention Layer
The best long-term solution is to create programming assignments that are hard to complete without AI but require students to understand the underlying concepts by having them implement their own prior work, implement algorithms under unusual constraints, or write lengthy documentation alongside their solutions. Such programming assignments will not prevent cheating via AI, but they will make it much more expensive to do so, while giving honest students more opportunities to demonstrate their knowledge.
Conclusion
Code detection is the next big frontier for AI-based academic integrity enforcement in AI research, and the tools are nowhere near ready. MOSS, the standard for three decades, does not even detect AI-generated code because AI provides a different solution that does not even resemble what peers have submitted. AI tools trained on natural language text use natural language perplexity metrics on syntax-constrained code. Even novice students who write genuine code for canonical problems produce code that is indistinguishable from AI-generated code. The state of AI-based code detection in 2026 is much less mature than that of natural language processing; however, the false-positive problem is just as large, and the consequences are just as critical for both CS educators and students.
Frequently Asked Questions
Can AI detectors accurately detect AI-generated code?
Partially, but not reliably enough for standalone enforcement decisions. There are significant false negatives for text-trained AI detectors on varied AI-generated code and significant false positives on beginner-level human code that tends to converge towards canonical patterns. Code-specific AI detectors that use CodeBERT-based perplexity approaches report AUC values of above 0.9 in controlled research environments. However, there are significant drops in accuracy when AI-generated code is varied by changing variable names or code structures. The best approach is a combination of MOSS for peer code similarity, code-specific AI detection for AI patterns, and human review of all code.
Why does MOSS fail against AI-generated programming submissions?
MOSS identifies similarities in structure. It was originally intended to identify instances in which students share code and make superficial changes, such as renaming variables. AI-generated code cannot be identified by MOSS, since each new AI-generated code solution has unique variable names, loops, and comments for the same problem. There is no unusual similarity between the AI-generated code and other codes that MOSS would identify. In fact, the creators of MOSS have always claimed that human judgment is necessary to interpret MOSS results as potential plagiarism. That has never been truer than today.
Do beginner students face false positives from code detection tools?
Yes, at higher rates than advanced students. The canonical solution space for introductory programming assignments is small. A correct solution to a linked list, a sorting algorithm, or other basic programming structures will look similar whether implemented by a human or an AI system. This is because both simply follow the assignment's functional requirements and share similar constraints on expressiveness. The distributions used to train AI detectors for distinguishing general AI from human behavior will not be able to differentiate between AI and human solutions when these distributions overlap heavily. This is the highest false-positive risk for students who are most likely to be programming well for the first time.
How does GitHub Copilot affect academic integrity policies?
GitHub Copilot creates a gray area in terms of policy because it spans from single-line autocomplete to function creation, and this spectrum includes both legitimate and illegitimate uses of the tool, according to most instructors. The issue is that current detection tools cannot make this distinction. A student who uses one suggestion from GitHub Copilot for a method signature while coding an otherwise original piece of work may trigger the same flags as a student who used GitHub Copilot to create their entire work. Institutions need clear policies on what is allowed and must be cited and what constitutes a violation, rather than simply issuing prohibitions that students cannot effectively follow.
What should CS instructors use instead of traditional code similarity tools?
The layered approach will be best utilized in 2026. MOSS will be used to detect similarities among peers. This is what it was originally designed to do. A code-specific AI detector will also be used. This detector will be calibrated to examples relevant to the assignment. Submissions must be made through Git with a history. This will provide an audit trail. The assignments will require individuality. This will include comments explaining what was done, as well as the student-designed test cases. Oral verification will also be used. The policy will also be specific regarding AI. None of these will be sufficient by itself. However, collectively, they will provide a system that is more effective than relying solely on automated detection. They will also be fairer to genuine students who happen to have written code similar to the AI's. Tools designed for AI text transformers address written assignments and documentation separately; the code itself requires code-specific approaches.