Most discussions of AI detection tools treat them as a single category: tools that scan text and return a probability score. But commercial AI detectors are optimized for one type of text: native English prose, casual prose, and academic prose. This works well only for the calibrated content types. It produces systematic errors with other types.
Domain-specific text, whether medical journal abstracts, legal contract clauses, technical scientific writing, or regulatory compliance documentation, has statistical properties that differ substantially from general English prose. General-purpose detectors trained on general corpora consistently misclassify domain-specific human writing at elevated rates and domain-specific AI-generated text at rates that differ from their headline accuracy figures suggest. For developers building custom detection pipelines, compliance teams evaluating institutional deployment, and specialized writers navigating detection in their fields, understanding how domain-specific detection works and where it fails is essential practical knowledge.
This guide covers the technical architecture of domain-customized detection, the fine-tuning process that builds domain-specific classifiers, the domains where commercial detectors systematically underperform, and the counter-strategy implications for writers in specialized fields. Using an AI text humanizer is not primarily a tool for disguising AI authorship in these contexts: it is a tool for correcting the systematic statistical bias that domain-specific detection introduces for genuine human writers in formal specialist registers.
Key Takeaways
General-purpose AI detectors systematically fail on domain-specific text. Research from 2025 explicitly documents that models trained on one text domain struggle to adapt to new domains. Medical, legal, and scientific writing has lower perplexity and a more uniform sentence structure than general prose, not because it is AI-generated, but because these are properties of formal specialist writing. A general-purpose detector trained on news articles and student essays will produce elevated false positive rates on medical journal text and legal contracts, even when those documents are written entirely by humans.
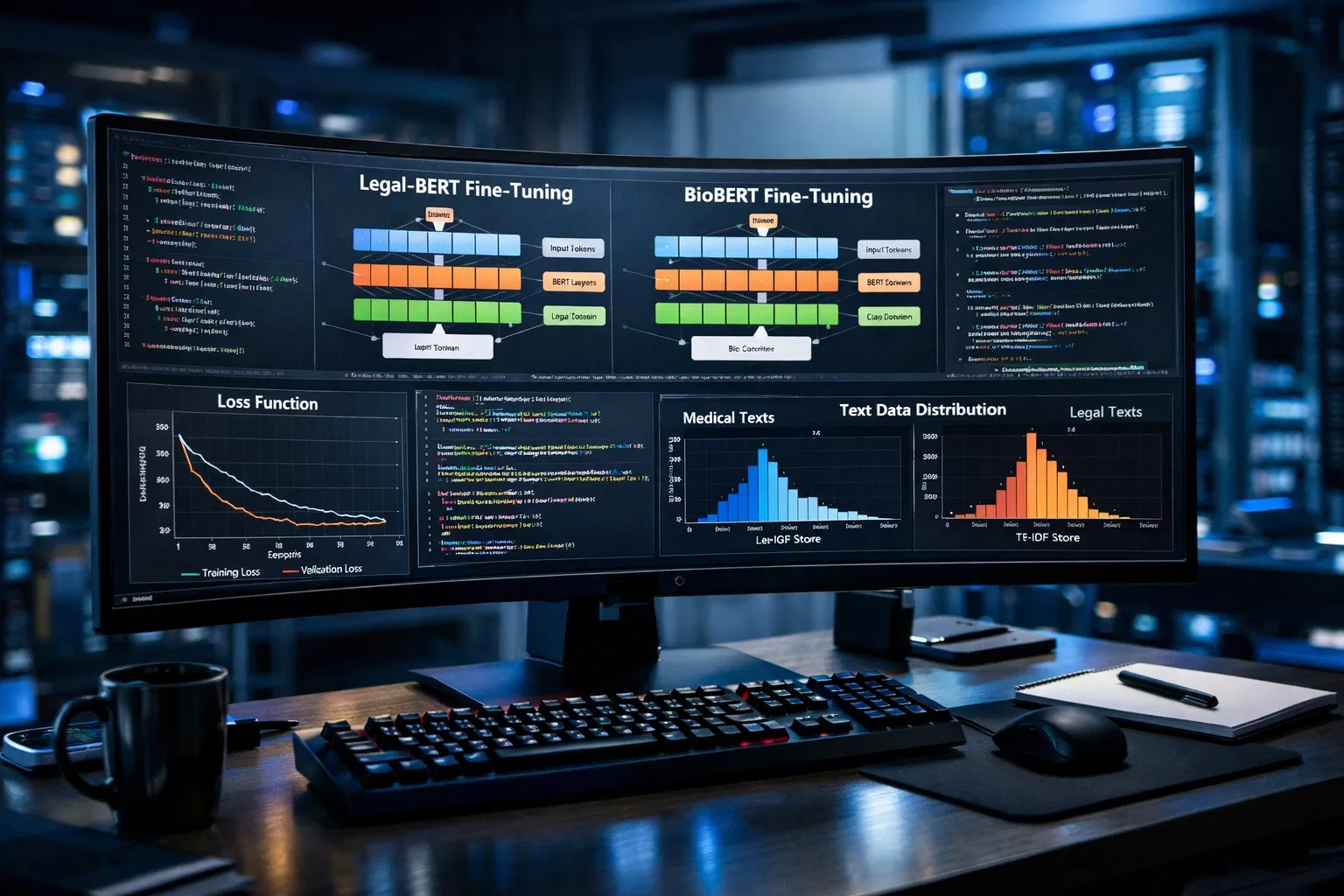
Domain-specific detectors are built through fine-tuning: a pre-trained language model such as BERT, RoBERTa, or their domain-adapted variants (Legal-BERT, BioBERT, or ClinicalBERT) is further trained on labeled examples of human-written and AI-generated text specific to the target domain. This process adapts the model's learned representations to the statistical distribution of the target domain, improving both sensitivity (catching AI content in that domain) and specificity (avoiding false positives in genuine human writing in that domain).
Domain-adapted base models already exist for major specialized fields. Legal-BERT and RoBERTa-Legal are pre-trained on legal corpora. BioBERT and ClinicalBERT are pre-trained on biomedical and clinical text. FinBERT is pre-trained on financial text. These domain models require less fine-tuning data to achieve good detection performance in their respective domains than fine-tuning general models from scratch, because their base representations already encode domain-specific vocabulary and syntactic patterns.
Domain-specific detection creates a sharper false positive problem for genuine human writers in those domains than general detection does. A domain-specific detector trained primarily on AI-generated medical text learns to distinguish AI-generated from human medical writing by exploiting the specific statistical patterns of AI-generated medical prose. If those patterns overlap with the formal, precise, low-variation style of expert human medical writers, the false positive rate for genuine human experts can be higher than the false positive rate for general-purpose detection on the same population.
The counter-strategy for writers in specialist domains is statistical humanization that targets the specific properties that domain detectors measure, rather than surface paraphrasing. A domain-specific detector is calibrated to human writing in that domain. Shifting the statistical profile of domain-specific text toward the measured properties of human domain writing, rather than toward general casual prose, is what produces reliable bypass. This requires a humanizer that adjusts perplexity and burstiness without distorting domain-specific vocabulary or technical precision. Using a tool that humanizes AI content in domain-sensitive contexts preserves technical accuracy while adjusting the statistical properties the classifier measures.
Why General-Purpose Detectors Fail on Domain-Specific Text
The failure of general-purpose detectors on domain-specific text is not a calibration oversight that better engineering would fix. It is a consequence of the fundamental structure of language models' text encoding and of how detection classifiers are trained.

The Distribution Mismatch Problem
A language model, whether used for generation or detection, learns the statistical distribution of its training corpus. BERT and RoBERTa were trained primarily on Wikipedia and BookCorpus, which are general English prose sources with diverse vocabulary, varied sentence structures, and natural burstiness. The perplexity baseline these models establish reflects that distribution. When a detection classifier is trained on human-AI pairs drawn from similar general corpora, it learns to distinguish AI text from human text within that distribution.
Domain-specific text follows an entirely different statistical distribution. Legal contracts use repetitive, formulaic clause structures by design. Medical journal abstracts require precise technical terminology with minimal stylistic variation. Scientific writing demands controlled, formal prose where personal voice and idiomatic expression are deliberately suppressed. These features, low perplexity, low burstiness, and consistent vocabulary, are precisely what detection classifiers trained on general corpora interpret as AI signatures. Research published in 2025 (Lekkala et al.) explicitly documented that models trained on one dataset struggle to adapt to new text domains, confirming that domain transfer is a genuine structural problem rather than a marginal calibration issue.
What the False Positive Rate Looks Like in Practice
Independent testing has found that when general-purpose detectors are applied to professional domain-specific text, legal contract language produces elevated AI scores because clause structures are formulaic and vocabulary is restricted; medical journal abstracts trigger false positives at rates substantially higher than their general human-text false positive rates because medical prose is precise, low-variation, and uses the technical vocabulary patterns that AI models also prefer; and scientific writing in STEM fields produces consistent false positive signals because objective, impersonal, methodologically constrained prose shares statistical properties with AI generation. To bypass domain AI detector false positives in these contexts, the solution cannot be to make specialist writing less specialized. It must target the statistical properties the detector measures while preserving domain vocabulary and precision.
How Domain-Specific AI Detectors Are Built
Building a domain-specific AI detection classifier follows the same general pipeline as other text classification tasks in natural language processing, with domain adaptation during base model selection.
Stage 1: Base Model Selection
Domain-specific fine-tuning 2025 identifies the core principle: select a base model whose pre-training corpus approximates the target domain's language distribution. For general AI detection, RoBERTa trained on diverse web text is the standard starting point. For domain-specific detection, the base model should already be adapted to the target domain's vocabulary and syntax. BioBERT (pre-trained on PubMed biomedical literature), ClinicalBERT (pre-trained on clinical notes), Legal-BERT (pre-trained on legal corpora), and FinBERT (pre-trained on financial text) are all open-source starting points for their respective domains. These models require significantly less labeled data for fine-tuning to achieve competitive domain-classification performance than fine-tuning a general model from scratch.
Stage 2: Training Data Construction
The fine-tuning dataset consists of labeled pairs of domain-specific human-written and AI-generated text, drawn from the same vocabulary distribution. For medical detection, this means human-authored biomedical abstracts paired with AI-generated abstracts on similar topics. For legal detection, human-written contract provisions are paired with AI-generated provisions in the same legal domain. The key quality requirement is that both human and AI samples genuinely represent the target domain's language: using general AI-generated text as negative examples in a medical classifier produces a model that detects general AI patterns rather than medical-context AI patterns.
Stage 3: Fine-Tuning
The domain-adapted base model is fine-tuned on the labeled pairs by adding a binary classification head and training with cross-entropy loss. Standard hyperparameter ranges are a learning rate between 1e-5 and 1e-4, batch sizes of 16 to 32, and 3 to 10 training epochs depending on dataset size. The classification head learns to map the base model's contextual embeddings of the input text to a probability of AI generation, calibrated to the target domain's statistical patterns. For an AI humanizer for medical writing to be effective against such a classifier, it must recognize that the target distribution is not general human prose but rather human medical prose and adjust accordingly.
Stage 4: Threshold Calibration
A classification model produces probability scores, not binary labels. The operating threshold at which a document is flagged as AI-generated is a design decision that trades sensitivity (catching more AI content) against specificity (flagging less human content). For high-stakes applications like medical journal review, the threshold should be calibrated to minimize false positives on domain-expert human writing. This requires evaluation against a held-out set of genuine human domain text, not general prose.
Domain-Specific Detection in Legal Text
Legal text presents some of the most distinctive domain-specific detection challenges of any professional writing category.
Why Legal Writing Triggers General Detectors
Legal writing is intentionally formulaic, repetitive, and low in variation. Contract clauses follow standardized templates. Court filings reuse established phrasings to track legal precedent. Regulatory documents repeat defined terms deliberately to avoid ambiguity. All of these features, formulaic structure, repeated vocabulary, low stylistic variation, and consistent sentence length, are precisely what general-purpose AI detectors associate with AI generation. A legal professional writing a contract in standard legal English will frequently trigger general-purpose AI detection tools regardless of whether AI was involved in the drafting.
Legal-BERT fine-tuning for classification demonstrates a domain-adaptation approach for legal text classification using Legal-BERT, a transformer model pre-trained on 12GB of legal corpora, including EU and UK legislation, European Court of Human Rights documents, and the US contracts corpus. Legal-BERT learns domain-specific legal vocabulary, the characteristic syntax of statutory interpretation, and the clause-level structural patterns of legal documents. When fine-tuned on a labeled legal text classification dataset, Legal-BERT outperforms general BERT models precisely because its base representations already encode the legal distribution, allowing the classification head to distinguish AI-generated legal text from human-written legal text within that specific distribution rather than against general prose.
Implications for Legal Writers
For lawyers, paralegals, and legal writers facing AI detection in their professional workflow, domain-specific legal detectors are both more accurate (at catching AI-generated legal drafts) and more discriminating (at distinguishing legal-register human writing from AI writing) than general detectors. A general-purpose detector is a blunt instrument in legal contexts. A Legal-BERT-based classifier is calibrated to the actual distribution of human legal writing. Using an AI humanizer for legal text appropriately means preserving the standard legal phrasing, clause structures, and defined-term repetition that courts and legal practice require, while adjusting the statistical variation in sentence construction and word-level predictability so that even a domain-specific classifier reads it as human legal writing.
Domain-Specific Detection in Scientific and Medical Writing
The Scale of AI Use in Scientific Writing
AI-written scientific manuscripts 2025 documents a striking fact: analysis of over 15 million biomedical abstracts from 2010 through 2024 indexed by PubMed found an abrupt increase in the frequency of characteristic AI-associated style words following the release of large language models. The excess-word analysis estimates that at least 13.5% of 2024 abstracts were processed using language models. Scientific publishing is simultaneously the domain where AI text detection has the strongest policy motivation and one of the domains where it is most difficult to calibrate correctly because human-expert scientific writing shares statistical properties with AI-generated scientific writing at high rates.
Why Medical and Scientific Writing Triggers Detection
The properties that make scientific writing trustworthy, such as science, objectivity, precision, standardized terminology, and methodological consistency, are the same properties that detection tools associate with AI generation. A well-written methods section describes experimental procedures in the passive voice, uses consistent technical vocabulary, and maintains a consistent sentence length. These are not signs of AI authorship. They are signs of a correct scientific writing style. BioBERT, fine-tuned on biomedical text, can distinguish the specific statistical patterns of AI-generated biomedical prose from human-expert biomedical prose better than a general detector, but even domain-specific detection faces genuine challenges at the frontier of human and AI scientific writing quality.
The Calibration Challenge
The challenge for compliance teams and journal editors deploying AI detection in scientific contexts is that calibrating for low false-positive rates means accepting more false negatives. A detector calibrated to avoid flagging genuine human expert writing in a formal scientific register will also allow more AI-generated scientific writing through, because the distributions overlap substantially. This is not a solvable engineering problem at the current state of the art. It is a consequence of the statistical overlap between human expert scientific writing and AI-generated scientific writing, an overlap that is growing as AI models improve. For humanized scientific AI text, this means the statistical adjustment target is already close to the distribution of human scientific writing, and the primary task is to preserve technical vocabulary, citation patterns, and methodological precision.
Enterprise Compliance Deployment of Domain-Specific Detection
Enterprise and institutional deployment of domain-specific AI detection serves several distinct compliance purposes, each with different accuracy requirements and tolerance for false-positive versus false-negative errors.
Academic and Research Integrity
Universities and research journals deploying AI detection for academic integrity purposes need very low false-positive rates, because a false positive results in an accusation of misconduct against a genuine researcher or student. Turnitin and GPTZero are both general-purpose tools that, as documented in the Perkins et al. 2024 research, achieve only 39.5 percent baseline accuracy on modern AI model output from GPT-5, Claude, and Gemini before any modification. For specialized academic fields where student and researcher writing naturally resembles AI output, institutions using general-purpose tools face systematic false-positive problems that domain-specific fine-tuned classifiers would reduce.
Content Authenticity Verification
Publishers of specialized professional content, including legal research services, medical information platforms, and financial advisory publications, have adopted AI detection as a quality gate for contributed content. These deployments benefit from domain-specific detection because the content they need to evaluate is domain-specific. A legal research database that checks submitted attorney analyses needs a legal-domain classifier, not a general-purpose tool calibrated on student essays. As AI detection compliance tools for verifying the authenticity of specialized content, domain-adapted classifiers produce more accurate and fairer results for both detecting AI-generated content and protecting genuine human domain experts.
Regulatory and Government Applications
Regulatory agencies that accept public comments, grant applications, or compliance filings face the challenge of evaluating domain-specific text for signs of AI involvement. Public comments on regulatory rule-making, grant proposals to scientific funding bodies, and regulatory compliance documentation all require detection calibrated to their specific writing domains. Applying a general-purpose detector to regulatory comment submissions produces false positives on the formal, standardized language that professional submitters use by convention. Domain-specific fine-tuned classifiers are the technically correct solution for these applications.
Domain-Specific Detection: A Field-by-Field Technical Reference
Domain | Why General Detectors Fail | Appropriate Base Model | Key False Positive Triggers | Detection Difficulty |
Legal | Formulaic clause structure, repeated defined terms, and low lexical variation by design | Legal-BERT and RoBERTa-Legal pre-trained on legal corpora | Contract boilerplate, statutory language, consistent citation formats | Moderate: Legal-BERT distinguishes AI legal from human legal better than general tools |
Medical / Clinical | Technical terminology, objective passive constructions, and consistent method descriptions | BioBERT (PubMed literature), ClinicalBERT (clinical notes) | Methods sections, diagnostic criteria, standardized reporting formats (CONSORT, PRISMA) | High: Expert human medical writing and AI medical writing overlap substantially |
Scientific / STEM | Formal register, precision vocabulary, minimal stylistic variation, standardized structure | BioBERT, SciBERT (scientific literature) | Abstract structure, results reporting, data-driven language patterns | Very high: Statistical overlap between human expert writing and AI is largest in STEM |
Financial / Regulatory | Standardized disclosure language, defined term repetition, and formulaic reporting | FinBERT (financial text), general BERT fine-tuned on financial filings | SEC filings language, compliance clause boilerplate, standardized disclosures | Moderate: Financial boilerplate is distinctive enough for domain-specific models to calibrate |
Technical Documentation | Precise, imperative prose, consistent terminology, low sentence variation | General RoBERTa fine-tuned on technical writing corpora | API documentation, procedure descriptions, specification writing | Moderate: Technical documentation has characteristic patterns separable from AI output |
General Academic | Formal academic register, thesis-evidence-conclusion structure, standard transitions | General RoBERTa or DeBERTa fine-tuned on student and academic writing | Five-paragraph structure, formal transitions, passive voice overuse | Low to moderate: Academic general tools like Turnitin are better calibrated for this domain |
The common thread across all high-difficulty domains is that the formal register required by professional convention produces writing that overlaps statistically with AI-generated text. An undetectable AI text domain strategy for these fields cannot simply rely on casual phrasing or colloquial vocabulary, as that would be professionally inappropriate. It must adjust perplexity and burstiness within the domain register.
False Positive Risks Specific to Domain-Adapted Detectors
Domain-specific detection creates a particular false positive problem that is in some respects worse than the false positive problem from general-purpose detection, because domain-adapted classifiers are calibrated to the specific distribution of expert domain writing. This calibration improves average accuracy but can create sharp false-positive spikes for specific subpopulations of domain writers.
The Expert Writing Problem
A domain classifier trained on a corpus of human medical writing learns the statistical properties of that corpus. If the corpus over-represents writing by non-native English speakers, the classifier may be calibrated to that population's statistical patterns. If the corpus over-represents writing from specific national or institutional traditions, the classifier may flag writing from other traditions as anomalous. The diversity of domain-expert writing within a single field is substantial, and a classifier trained on a single sample of that diversity will systematically misclassify subpopulations whose writing differs from the training distribution, even though all are genuine human experts.
Temporal Drift
Domain-specific classifiers face a temporal drift problem: the statistical properties of AI-generated domain text change as AI models improve. A Legal-BERT-based classifier trained in 2024 on GPT-4 legal output may not correctly classify GPT-5 or Claude 3.5 legal output, because newer models produce more human-like text in all domains. The classifier needs continuous retraining against the current AI model output to maintain accuracy. Without retraining, domain-specific classifiers may become less effective at detecting AI content over time while potentially becoming more likely to flag human expert writing that resembles the increasingly human-like AI output they were trained to detect.
For domain writers facing these problems, a domain false-positive humanizer approach means adjusting the statistical profile of genuine human domain writing to align with what current versions of the deployed classifier read as human writing, accounting for the classifier's specific calibration rather than targeting general human prose distributions.
The Counter-Strategy: Domain-Aware Statistical Humanization
For writers in specialized domains whose genuine human writing triggers domain-specific AI detectors, or for writers using AI assistance in specialized domains whose output needs to pass domain-specific detection, the counter-strategy is domain-aware statistical humanization: adjusting perplexity and burstiness within domain-appropriate registers rather than shifting toward general, casual prose.
Why General Humanization Fails in Domain Contexts
Most AI humanizer tools are calibrated to move text toward general human prose characteristics: more variable sentence lengths, more idiomatic vocabulary, and more informal transitions. Applied to medical or legal text, this approach is counterproductive: it introduces vocabulary and stylistic patterns that are inappropriate for the domain, makes the text read as less professionally competent, and may actually increase AI detection scores if the domain classifier is calibrated to distinguish professional-register human writing from informal-register text that would be anomalous in that domain.
What Domain-Aware Humanization Looks Like
Domain-aware humanization adjusts perplexity within domain vocabulary constraints: introducing less common technical synonyms or alternative phrasings that are professionally appropriate but statistically less predictable. It varies sentence structure within the grammatical patterns conventional in the domain, mixing complex subordinate clauses with shorter declarative sentences in a way consistent with high-quality human domain writing. And it preserves the domain markers that a well-calibrated domain classifier associates with genuine human writing: specific citation patterns, appropriate hedging language, methodologically correct terminology.
ModernBERT fine-tuning classifier 2025 documents that modern encoder classifiers, including ModernBERT trained on 2 trillion diverse tokens, including web documents, code, and scientific articles, achieve high accuracy with fast processing speeds and generalize better across domains than earlier BERT variants. As domain-specific classifiers improve, the counter-strategy for domain writers must similarly improve: statistical humanization must produce text that falls within what the most sophisticated domain-specific classifier reads as human domain writing, not just what a general-purpose detector reads as human. An AI humanizer detection bypass solution for domain writers needs to target the specific properties of human writing in their domain rather than generic human writing properties.
Practical Guidance by Audience
For Developers Building Custom Detection Pipelines
Select a domain-adapted base model rather than fine-tuning a general BERT or RoBERTa model from scratch. Legal-BERT, BioBERT, ClinicalBERT, and FinBERT all provide domain-specific starting points that require less labeled data and fewer training epochs to achieve competitive domain classification performance. Construct your training data from genuinely domain-specific human-AI pairs: general AI-generated text does not function as a valid negative example in a domain classifier. Calibrate your operating threshold against a held-out set of genuine domain-expert human writing to establish an acceptable false positive rate before deployment. Plan for continuous retraining as AI models improve and the statistical properties of AI domain text evolve.
For Compliance Teams Evaluating Deployment
Before deploying any AI detection tool in a specialized professional context, test it against a sample of your organization's genuine human-written content in that domain. If the general-purpose tool produces a false-positive rate above 5 percent on your human-written sample, it is not appropriate for high-stakes deployment in that context without either threshold adjustment or replacement with a domain-adapted alternative. Establish a process for human review of any submission flagged for detection before taking adverse action. Detection scores in specialized domains carry even less evidentiary weight than detection scores in general writing contexts, and the false positive problem is systematically worse.
For Specialized Writers Facing Domain Detection
Understand that your formal domain writing style is a systematic false positive trigger for general-purpose detectors and may be a trigger for domain-specific detectors as well. The most appropriate protective measure is statistical humanization that preserves your domain-appropriate register while adjusting the perplexity and burstiness properties that detection classifiers measure. Using a free AI humanizer to address false positives in genuine human-domain writing is appropriate when the tool adjusts statistical properties without distorting domain-specific vocabulary, technical precision, or professional appropriateness.
Solution Section: Besthumanize for Domain-Specific Contexts
BestHumanize addresses the statistical layer of domain-specific AI detection: it adjusts the perplexity and burstiness metrics measured by both general and domain-specific classifiers, without requiring writers to modify their domain-appropriate vocabulary, technical terminology, or professional register. For specialists in medical, legal, or scientific writing, this is the critical capability: a humanizer that reduces measurable AI signatures in formal-domain text without introducing informality, imprecision, or inappropriate vocabulary.
The tool processes any text for free, without requiring an account or imposing per-session word limits. For domain writers who need to check and adjust their own genuine human writing that triggers false positives, or who use AI assistance in their specialized domain and need the output to pass detection, BestHumanize provides a statistical adjustment layer at no cost. The best AI humanizer, with specialized domain context, is one that adjusts measurable properties without altering the substantive content that makes domain writing professionally credible. That is the design constraint within which BestHumanize operates.
Important Note on Domain Vocabulary: When using any statistical humanizer on highly technical domain text, review the output carefully before submission. Statistical adjustment tools may occasionally substitute synonyms that are semantically close in general English but technically incorrect in domain usage. For example, substituting a medical term with a non-standard variant, or introducing a paraphrase of a defined legal term that loses its precise legal meaning, would create problems beyond detection scores. Review technical vocabulary specifically after humanization to confirm domain precision is intact. |
Conclusion
Domain-specific AI detection customization is a technically sophisticated response to a real problem: general-purpose detectors fail on specialized professional text because they are calibrated to a different statistical distribution from the text they evaluate. The solution on the detection side is domain adaptation via fine-tuning, using domain-pretrained models such as Legal-BERT, BioBERT, or FinBERT as the base for classifiers trained on domain-specific human-AI text pairs. The solution for writers facing these systems, whether the detector is general-purpose or domain-adapted, is statistical humanization that targets the properties the classifier measures while preserving the domain-specific vocabulary, register, and technical precision that makes domain writing professionally credible. Understanding both sides of this technical landscape, how detectors are built and how their measurements can be addressed, is the foundation for navigating domain-specific AI detection in 2026.
Frequently Asked Questions
Why do general-purpose AI detectors fail on medical, legal, and scientific text?
General-purpose AI detectors are trained on corpora of general English prose, primarily news articles, web content, and student writing. These corpora establish a baseline for what human writing looks like statistically: variable sentence lengths, diverse vocabulary, natural burstiness, and variation in perplexity. Domain-specific professional text, including medical journal abstracts, legal contract language, and scientific methods sections, exhibits low lexical variation, consistent sentence structure, and high technical vocabulary precision in line with professional conventions. These are the same statistical properties that general-purpose detectors associate with AI generation. Research from 2025 (Lekkala et al.) found that models trained on a single text dataset struggle to adapt to new text domains, confirming that general-purpose detectors systematically misclassify specialist-domain writing at elevated false-positive rates. This is not a calibration error that better engineering resolves: it is a consequence of the statistical distance between general and domain-specific text distributions.
How is a domain-specific AI detector built using fine-tuning?
Building a domain-specific AI detector follows a transfer learning pipeline: select a pre-trained base model whose training data approximates the target domain (Legal-BERT for legal text, BioBERT for biomedical text, general RoBERTa for technical documentation); construct a labeled training dataset of domain-specific human-written text paired with domain-specific AI-generated text; add a binary classification head to the base model; and fine-tune the combined model on the labeled pairs using cross-entropy loss. Standard hyperparameters are a learning rate between 1e-5 and 1e-4 and 3 to 10 training epochs. The classification head learns to distinguish AI-domain text from human-domain text within the domain's specific statistical distribution, rather than against a general text distribution. Threshold calibration against a held-out human-domain writing sample then sets the operating point that balances sensitivity and the false-positive rate for the specific deployment context.
What pre-trained domain models exist for legal, medical, and scientific text classification?
Several domain-adapted transformer models are publicly available on Hugging Face for fine-tuning. Legal-BERT and RoBERTa-Legal are pre-trained on legal corpora, including EU and UK legislation, European Court of Human Rights documents, and US contracts. BioBERT is pre-trained on PubMed biomedical literature abstracts and PMC full-text articles. ClinicalBERT is pre-trained on MIMIC-III clinical notes and is specifically adapted to the language of clinical documentation. SciBERT is pre-trained on scientific publications across multiple disciplines. FinBERT is pre-trained on financial news and filings. These models provide domain-calibrated language representations that reduce the amount of labeled data needed to achieve competitive classification accuracy in their respective domains, compared to fine-tuning a general-purpose model from scratch.
What false positive risks do domain-specific detectors create for genuine specialist writers?
Domain-specific detectors pose several risks of false positives for genuine human domain writers. First, sub-population calibration risk: if the classifier was trained on a non-representative sample of human-domain writing, it will flag genuine human writing that differs from that sample, even within the same domain. Second, temporal drift risk: as AI models improve and produce more human-like domain text, classifiers trained on older AI output may become both less effective at catching AI content and more likely to flag formal human expert writing that resembles the increasingly human-like AI outputs they were trained to detect. Third, expert-formality risk: very high-quality, formally correct domain writing may be scored more closely to AI-generated domain writing in domain-specific classifiers because AI models also optimize for technically correct, formal domain writing. These risks mean that even domain-adapted classifiers should not be used as sole evidence of AI authorship in high-stakes professional contexts.
What is the counter-strategy for writers whose domain-specific style triggers detection?
The correct counter-strategy for domain writers is domain-aware statistical humanization: adjusting perplexity and burstiness within domain-appropriate language conventions rather than toward general casual prose. General humanizer tools that introduce informality, idiomatic vocabulary, or colloquial transitions are inappropriate for domain text: they make the writing less professionally credible and may not address what the domain-specific classifier is measuring. Domain-appropriate humanization introduces statistical variation through less common technical synonyms that remain professionally precise, maintains consistent sentence structure with high-quality human domain writing, and adjusts specific word-level predictability patterns measured by the classifier without distorting domain vocabulary or technical accuracy. BestHumanize provides this statistical layer free of charge, without account creation, and carefully reviews the output to preserve domain vocabulary after processing. Using an AI text humanizer tool appropriately in domain contexts means preserving technical precision while adjusting the statistical properties measured by domain-calibrated classifiers.