Most discussions of AI humanizer tools focus on the results: did the text pass GPTZero, did it get through Turnitin, does it read naturally? These are the questions that matter to users. But understanding why the results come out the way they do, why some tools consistently outperform others, and why basic paraphrasing fails while statistical adjustment succeeds requires going one level deeper into the technology.
This article explains the technical foundation of both AI detection and AI humanization. What measurements do detectors actually take? What statistical properties distinguish AI-generated text from human writing at the level that detection models evaluate? What specifically does a humanizer do to those properties, and why does the approach matter so much for whether it works? And what does the ongoing arms race between detection and humanization technology look like in 2026?
This is not a review of individual tools. It explains the underlying mechanisms that determine how well any AI text humanizer can perform. Understanding these mechanisms helps writers make better decisions about which tools to use, how to use them, and what their fundamental limits are.
Key Takeaways
AI detection tools do not read words the way humans do. They measure statistical properties of text: primarily how predictable each word choice is given the preceding context (perplexity), how much sentence length and structure vary throughout the document (burstiness), and a range of stylometric features including lexical diversity, part-of-speech patterns, and discourse-level consistency. These are mathematical measurements of the text's statistical fingerprint, not semantic evaluations of what the text says.
Language models generate text by predicting the statistically most probable next token at each step. This process produces text with characteristically low perplexity: the word choices are systematically more predictable than human writing because they reflect the highest-probability completions at each position. This predictability is the primary signal that detectors exploit. It persists across AI models and is not eliminated by using longer prompts, more specific instructions, or higher-quality models.
Paraphrasers fail to bypass detection because synonym substitution and sentence rearrangement do not meaningfully change the statistical properties that detectors measure. Replacing "significant increase" with "considerable rise" does not change how predictable the word sequence is or how variable the sentence structure is. The text looks different to the eye but is statistically almost identical to the original.
True humanizers work by targeting the statistical properties directly: introducing controlled unpredictability in word choice to raise perplexity, varying sentence length and structure to create natural burstiness, and removing the stylistic fingerprints specific to particular AI models. This approach changes the text's measured statistical profile, not just its surface appearance.
The arms race between humanizers and detectors is real and ongoing. Detector developers actively collect outputs from popular humanizer tools, label them as AI-generated, and retrain their models on that data. Humanizer patterns that work today may be detectable tomorrow. This creates an ongoing dynamic where tool quality, update frequency, and technical approach all determine reliability over time.
The most effective detection evasion combines statistical humanization with genuine human editing. Manual editing adds the authentic voice, first-hand perspective, and content-level variation that statistical adjustment alone cannot produce. Using a tool that can humanize AI content statistically as part of a larger editing workflow, not as a standalone replacement for human judgment, is the technically sound approach.
How AI Detection Actually Works
To understand what humanizers are doing, you first need to understand what detectors are measuring. Detection tools are not reading your text the way a teacher would. They are running statistical and machine learning analyses on the text as a data structure.
The Language Model Core
Every major AI detection tool uses one or more language models in its detection pipeline. The central principle is that an AI model is itself the best detector of AI-generated text: it knows what the most probable next word is at any position in the sequence, and AI-generated text selects those high-probability words far more consistently than human writing does. This is a practical perplexity measurement.
A detection tool takes your text and runs it through its own language model, computing how surprised the model is at each word choice. Low surprise throughout the document means the text is predictable, as AI output is. A great or variable surprise means the text is using words less predictably, as humans do. The perplexity score is a mathematical summary of this measurement across the entire document.
Classifier Models
Beyond simple perplexity measurement, modern detectors use trained classifiers that have learned to distinguish human writing from AI writing from thousands to millions of examples. These classifiers, often based on transformer architectures like RoBERTa, learn statistical patterns that characterize AI writing across dimensions beyond perplexity: sentence-length distributions, the variance of those distributions (burstiness), lexical diversity, part-of-speech bigram frequencies, and discourse-level coherence patterns. The classifier outputs a probability: given all these measured features combined, how likely is this text to have been generated by an AI model?
The AI humanizer complete guide explains the core detection signals precisely: low perplexity (predictable word sequences) combined with low burstiness (uniform sentence variation) together form the primary statistical fingerprint that classifiers have learned to associate with AI-generated text. The combination matters because the individual signals are not definitive on their own. A human writer can produce a short stretch of predictable text or a short stretch of very uniform sentences. What is statistically distinctive is producing it consistently across a full document, which is what language models do by construction.
Why the Text Length Matters
Detection accuracy improves with text length, and this is not arbitrary. Individual sentences provide insufficient statistical data for reliable measurement. Over hundreds or thousands of words, the compounding probability patterns become statistically significant and much harder to fake. A short paragraph might plausibly occur in human writing even if every sentence is AI-patterned. An entire essay or article produced by the same statistical process becomes identifiable through the cumulative weight of evidence. This is why detectors are more accurate on longer documents and why testing humanizers on short paragraphs produces better-looking results than testing on full documents. Reliably bypassing AI detectors on full-length documents requires genuine statistical adjustments across the entire text, not just surface-level changes.
Perplexity: The Core Detection Signal
Perplexity is the most fundamental property that AI detection tools measure, and understanding it precisely clarifies both why AI text is detectable and what humanizers need to do about it.
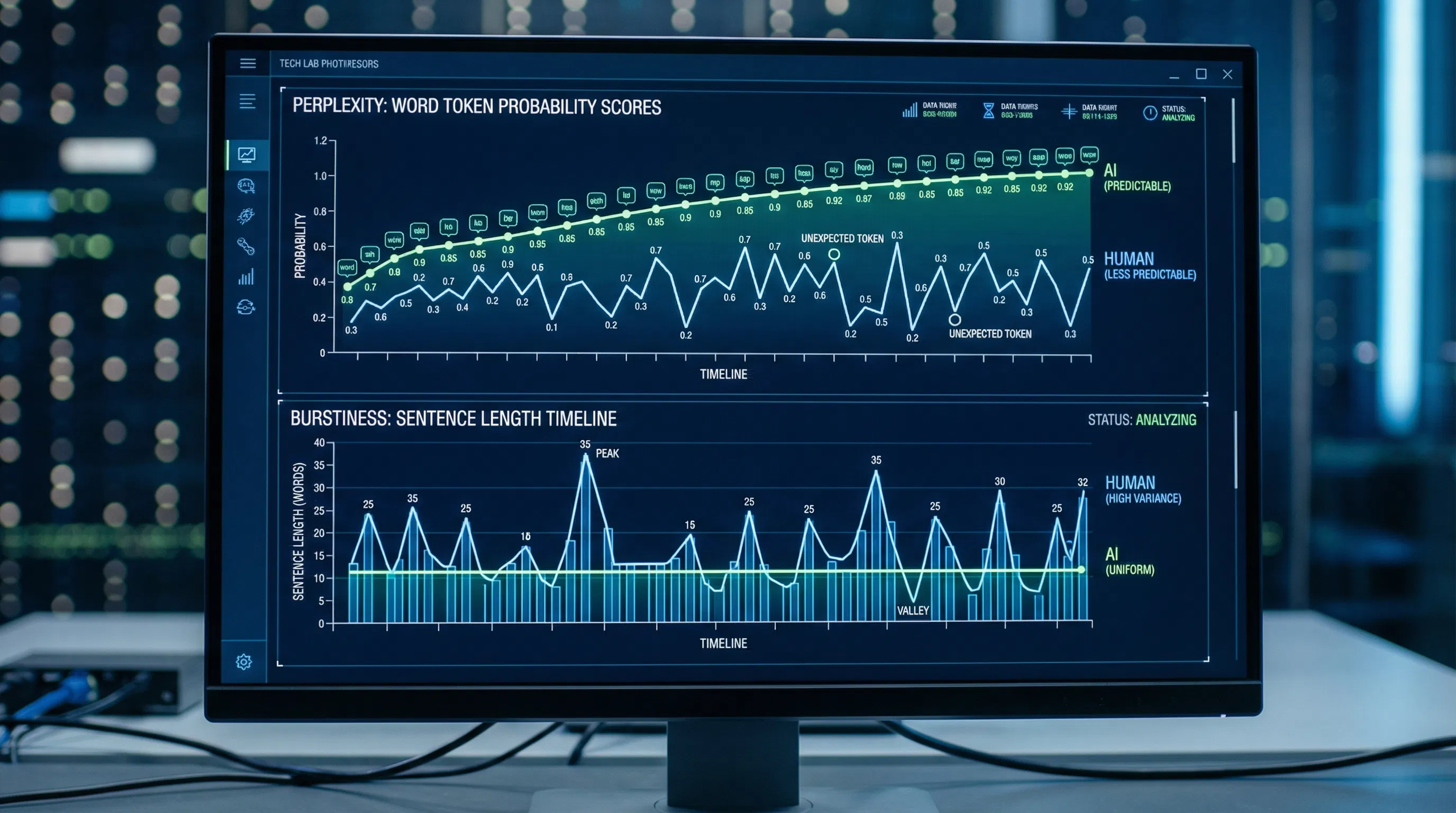
What Perplexity Measures
In information theory and natural language processing, perplexity measures how well a probability model predicts a sequence of tokens. For a language model, it is effectively the reciprocal of the geometric mean of the probability the model assigns to each word in the sequence, given all the words that came before it. High perplexity means the model was frequently surprised by the word choices. Low perplexity indicates the model could have accurately predicted most word choices.
Human writing has relatively high perplexity because humans make creative, idiosyncratic, and context-driven word choices that language models have not yet learned to predict reliably. A human might write, "The meeting went about as well as a dentist appointment in a war zone." No language model would generate that metaphor because it is not the most probable continuation in any professional writing context. AI-generated text, produced by selecting the highest-probability next tokens at each step, has lower perplexity because the model systematically selects the most expected words.
Why Perplexity Alone Is Insufficient
Perplexity is not a binary signal, and skilled human writers can inadvertently produce low-perplexity text. When someone writes clearly and directly, avoiding unusual vocabulary and complex constructions, their word choices fall within the range of statistical probability. Academic and professional writers, in particular, tend toward formal, conventional vocabulary that yields lower perplexity than creative or casual writing. This is the primary source of false positives: human writing in formal registers shares perplexity characteristics with AI-generated text.
Using an AI humanizer tool to raise the document's measured perplexity by introducing strategically varied, less predictable word choices at specific positions shifts the text's statistical profile away from the AI-generated range. The goal is not to make every word choice unusual, which would damage readability, but to introduce enough variation that the document's aggregate perplexity score falls within the human writing distribution.
Burstiness: The Rhythm Signal
Burstiness is the second major statistical property that AI detection tools measure, and it captures something qualitatively different from perplexity. Where perplexity measures predictability at the word level, burstiness measures consistency at the sentence level.
What Burstiness Captures
Human writing has a natural rhythm that varies throughout a document. Writers unconsciously alternate between short, punchy sentences and longer, more elaborated ones. They use fragments for emphasis. They break register and tone occasionally. They ask rhetorical questions. They start some sentences with conjunctions. These variations in sentence length and structure are not random noise; they reflect the genuine variation in how human thought unfolds as it is expressed in writing.
AI language models produce text with much more uniform sentence structure. Because each sentence is generated token-by-token to complete a statistically probable pattern, the resulting sentences tend toward similar lengths and grammatical structures. There are exceptions, and newer models produce more variation than earlier ones, but the statistical tendency toward uniformity persists. Over a full document, the variance in sentence length is measurably lower for AI-generated text than for human writing. This is what burstiness measures: the variance in sentence-level perplexity or length across the document. High burstiness means the text shifts patterns frequently. Low burstiness means it is consistent, which is the AI signature.
How Humanizers Address Burstiness
Humanizers that address burstiness analyze the input document's sentence structure and restructure it to introduce more variation. This involves several operations: merging short, consecutive sentences into a more complex structure, splitting long, uniform sentences into shorter fragments, varying sentence openings so they do not all follow the same grammatical template, and occasionally introducing rhetorical questions or incomplete constructions to break the uniform flow. The key is that these structural changes must preserve meaning while producing measurable differences in the distributions of sentence length and complexity.
A developer-focused breakdown of this process: to beat AI detectors through burstiness adjustment, the target is mixing sentences of 5 to 10 words with sentences of 15 to 20 words and occasional 25-plus-word structures, varying sentence beginnings across different grammatical forms, and incorporating questions, exclamations, or other non-declarative structures alongside the standard declarative sentences that AI models default to.
Stylometric Analysis: The Deeper Detection Layer
Beyond perplexity and burstiness, advanced detection tools apply stylometric analysis: the quantitative study of writing style across a range of linguistic features that go beyond individual word choice or sentence length.

What Stylometric Features Detectors Measure
Stylometric AI detection examines the statistical distribution of features, including type-token ratio (the ratio of unique words to total words, measuring lexical diversity); part-of-speech bigrams (how often specific pairs of grammatical categories appear together, capturing syntactic patterns); function word frequency (the relative usage of prepositions, articles, conjunctions, and other grammatical words that vary systematically between AI and human writing); and discourse-level coherence markers (how sentences connect to each other through reference, contrast, and elaboration). Research from AAAI 2025 on AI text detection found that models combining stylometric features with transformer-based embeddings achieve detection accuracy in the high 90s on unmodified AI content.
Why AI Models Have Stylometric Signatures
Each major AI model, ChatGPT, Claude, Gemini, and others, has characteristic stylometric patterns that emerge from its training data, architecture, and generation strategy. ChatGPT in particular has documented patterns: it overuses phrases like "delve into," "it is worth noting," "in conclusion," and "tapestry." It defaults to specific transition patterns and paragraph structures. These fingerprints are consistent enough that stylometric analysis can often identify not just that text is AI-generated but which model generated it.
Humanizers that operate at the stylometric level specifically identify and remove these model-specific fingerprints. This is a separate operation from perplexity adjustment or burstiness introduction. A tool might successfully raise the perplexity of a ChatGPT text and vary its sentence lengths but still leave the characteristic transition phrases, the formal coherence markers, and the specific part-of-speech bigram patterns that stylometric classifiers are trained to detect. Comprehensive humanization needs to address all three layers: word-level perplexity, sentence-level burstiness, and document-level stylometric fingerprints. Reducing AI detection across all dimensions requires all three.
The Technical Architecture of AI Humanizers
Understanding what a humanizer is doing under the hood clarifies why different tools produce such different results from the same input.
Surface-Level Paraphrasers
The simplest tools in the humanizer space are effectively paraphrasers: they substitute synonyms, rearrange clauses, and change active to passive voice or vice versa. These operations alter the text's surface appearance but do not address its underlying statistical properties. Replacing "significant" with "substantial" does not change the probability distribution of the surrounding sequence. Rearranging "the team achieved the goal" to "the goal was achieved by the team" does not change the sentence length or the stylometric fingerprint. Detection accuracy on paraphraser output drops modestly from unedited AI text (typically from 97 to around 60 percent), but the text remains firmly in the flagged range for any major detector.
Statistical Targeting Models
The NLP AI text humanization guide outlines the technical operations that separate genuine statistical humanizers from paraphrasers. A true humanizer implements deliberate perplexity control, selecting word choices that are less statistically probable while remaining contextually coherent and semantically correct; burstiness injection through sentence length diversification across the full document; stylistic fingerprint removal targeting the specific high-frequency patterns associated with the source AI model; and lexical diversity expansion, maintaining 70 to 80 percent vocabulary consistency while varying 20 to 30 percent of descriptive and transitional vocabulary.
Detector-Guided Humanization
The most sophisticated humanizers use a feedback loop with a built-in detection model in their pipeline. Rather than applying a fixed transformation, they run the input through a detection classifier at each step and select transformations that most reduce the detected AI probability at each position. This adversarial training approach produces texts that are specifically optimized against the detection models they are trained against. Research on adversarial paraphrasing shows that detector-guided generation produces texts that generalize across different detectors, because most high-quality detectors are calibrated to the same underlying distribution of human writing. When the humanizer adjusts text toward that distribution, the adjustments carry over across detectors, even if they were guided by only one detector.
Using an AI content humanizer based on this architecture produces fundamentally different results from paraphrasers because the optimization target is the statistical signature itself, not the surface words.
Surface Paraphrasing Versus Deep Statistical Humanization
What Changes | Surface Paraphrasing | Statistical Humanization |
Word vocabulary | Synonyms substituted; similar probability distribution maintained | Intentionally less probable word choices were introduced; perplexity rose. |
Sentence length | Generally preserved; rearrangement may add or remove a few words | Document-wide distribution restructured; deliberate length variation introduced |
Sentence structure | Active/passive swaps; clause rearrangement; minor syntax changes | Sentence type diversity added: fragments, questions, complex-simple alternation |
Model fingerprints | Not addressed; characteristic phrases and patterns preserved | Specifically identified and removed; platform-specific language patterns eliminated |
Part-of-speech patterns | Unchanged; grammatical category frequencies preserved | Adjusted to match human writing distributions across clause types |
Lexical diversity | Limited improvement; synonym substitution stays in the same register | Deliberate vocabulary range expansion across descriptive and transitional vocabulary |
Effect on GPTZero | Drops from ~97% AI to ~60%; still firmly flagged | Can drop below 10%; reaches "likely human" range with good tools |
Effect on Turnitin | Minimal; Turnitin explicitly tracks QuillBot-style processing | Significant stylometric adjustment required for reliable Turnitin bypass |
Meaning preservation | High-level surface changes rarely alter meaning | Good quality tools. Aggressive modes in weaker tools can introduce drift |
10 AI humanizers tested were ranked and found that tools targeting statistical properties, including burstiness and perplexity, achieved bypass rates approximately twice as high as tools relying on basic paraphrasing. The bypass rate gap between the best-performing true humanizers and the best-performing paraphrasers was approximately 30 percentage points in their testing. Producing truly undetectable AI text requires a statistical approach, not a surface one.
The Arms Race: How Detectors Adapt to Humanizers
The relationship between humanizer tools and detection tools is genuinely adversarial, and understanding how each side adapts helps clarify why no single tool or approach can produce reliable results indefinitely.
How Detectors Adapt to Humanizers
Detection tool developers actively monitor the outputs of popular humanizer tools. When a humanizer produces a consistent output pattern, that pattern gets added to the training data for detection classifiers, labeled as AI-generated or AI-humanized. The detector then learns to identify that specific humanizer's output style. Turnitin announced in late 2025 that it had developed specific detection for QuillBot-processed text, having trained on a large corpus of QuillBot outputs. This is the arms race in practice: a humanizer establishes a pattern, the detector learns that pattern, and the humanizer must update its approach.
What Humanizers Do in Response
Humanizer tools respond by updating their models, diversifying their output patterns to avoid consistent signatures, and incorporating detection testing into their pipeline so output is verified against the target detectors before being returned to the user. Some tools support multiple processing modes because different modes produce distinct output patterns, making it harder for detectors to characterize the tool's signature. Adversarial training against the latest detector versions is the state of the art in humanizer development.
The three-pillar humanization approach outlines the three technical dimensions a humanizer must address to stay ahead in the detection arms race: burstiness injection (sentence variation), perplexity reduction (controlled-vocabulary unpredictability), and stylistic fingerprint removal (eliminating model-specific patterns). A tool that excels at one or two but neglects the third will have a specific vulnerability that detectors can learn to exploit. The most durable tools address all three simultaneously and update their models against current detector versions.
The Fundamental Limits
No humanizer can produce text that is guaranteed to pass all detectors at all times. Detectors update continuously. A humanizer's effective bypass rate is always measured against a specific version of a specific detector. The text that passes GPTZero version X may not pass GPTZero version X+1 if the new version was trained on outputs from the humanizer you used. This is why manual editing remains irreplaceable as the final layer: genuinely human-added content, specific experiences, an authentic voice, and a first-hand perspective are elements that no statistical adjustment can substitute for and no detector can reliably flag as AI-generated. AI detection-bypass tools target the statistical layer. Human editing addresses the content layer. Both are necessary for robust results.
Why False Positives Happen and What They Mean for the Technology
A technical understanding of how detection works also explains why false positives are not an edge case but a structural feature of the technology. Any detection system calibrated to identify AI-generated writing must define a boundary in statistical space. Human writing and AI writing occupy overlapping distributions in that space. A detector's threshold is always a trade-off between sensitivity (catching more AI writing) and specificity (not flagging more human writing).
The statistical properties that characterize AI writing, low perplexity and low burstiness, also characterize human writing in specific contexts: formal and academic registers, professional documents, writing by non-native English speakers, and writing by skilled professionals whose clear, direct style produces more predictable word choices. When a detector calibrates on these properties, it systematically produces higher false-positive rates for these writing populations. The Stanford Liang et al. study, which found that over 61 percent of non-native English essays were misclassified as AI-generated, is a direct consequence of this statistical overlap.
An AI humanizer addresses false positives by adjusting the statistical properties of genuine human writing toward the measured ranges detectors associate with human writing, rather than those associated with AI writing. This is not concealing AI authorship. It corrects a systematic measurement bias by ensuring the text's statistical signature matches that of its actual human authorship. The technology works the same way regardless of whether the input text was generated by an AI or written by a human who writes in a formally precise style. Tools that humanize AI writing adjust statistical properties without altering content serve both populations for the same technical reason.
What Good Humanizer Technology Looks Like
Given this technical context, the specific properties that distinguish a well-designed humanizer from a poor one are identifiable and evaluable.
Multi-layer statistical targeting. A good humanizer addresses perplexity, burstiness, and stylometric fingerprints simultaneously. Tools that only address one or two leave detectable gaps. The detection classifiers evaluate all three dimensions, so a bypass that addresses only two is partial and inconsistent.
Detector-guided feedback. The best humanizers incorporate a detection model into their processing loop, running outputs against a classifier and selecting transformations that move the text toward the human-writing distribution. This approach produces output that generalizes across detectors rather than being calibrated to one specific tool.
Meaning preservation under transformation. Statistical adjustment must operate on linguistic form while preserving semantic content. A humanizer that changes what the text says, introduces factual errors, or distorts arguments is not a quality tool, regardless of its detection-bypass rate. Meaning preservation under aggressive statistical transformation is technically difficult and is what separates quality tools from cheap alternatives.
Continuous model updates. Given the arms-race dynamic, a humanizer that does not update its models to keep pace with current detector versions will degrade in effectiveness over time. Update frequency and specificity to current detector versions are indicators of tool quality that are not visible in marketing claims but are visible in consistent real-world bypass results over time.
No data retention. The text you submit to a humanizer may contain sensitive content. A tool that stores your submissions uses them to train future models, which is problematic for both privacy and the detection arms race (stored patterns eventually end up in detector training data). A free AI humanizer with zero data retention addresses both concerns.
Solution Section: Applying the Technical Understanding
The technical understanding in this article translates into concrete, practical guidance for writers.
Choose Tools That Target Statistics, Not Surfaces
Before using any humanizer, verify that it explicitly targets perplexity and burstiness rather than just performing synonym substitution and paraphrasing. A tool that cannot describe its approach in terms of the statistical properties it adjusts is almost certainly a surface paraphraser. The difference in bypass performance is approximately 30 percentage points in controlled testing. This is the most consequential choice a writer can make in the humanizer selection process.
Use the Full Editing Workflow
Statistical humanization addresses the measurable properties that detectors evaluate. It does not address the content dimensions that human readers evaluate: first-hand experience, authentic voice, specific personal detail, original analysis, and genuine expertise. The optimal workflow is: draft or generate content, apply statistical humanization, and then perform human editing to add the content-level qualities that neither an AI model nor a humanizer can provide. The Perkins et al. 2024 study found that manual adversarial techniques reduced detector accuracy from 39.5% to 22.1%. Adding statistical humanization on top of manual editing further drops it. Both together produce the most reliable results.
For ESL and Formal-Style Writers
Writers whose genuine human writing is systematically flagged due to formal register or ESL writing patterns should understand that statistical humanization corrects a bias in the detection system rather than misrepresenting their authorship. The statistical properties that detectors associate with AI writing also characterize authentic human writing in these contexts. Applying humanized neurodivergent writing or formal-style writing to shift its statistical profile toward the human-writing distribution detected by these tools is the technically correct response to a systematic calibration problem in the detection tools themselves.
Verify Output with External Detectors
Always run humanized output through at least one external detector before submitting high-stakes content. Internal detectors embedded in humanizer platforms may be calibrated to favor that tool's own output more than external detectors are. Use the same detector your institution or platform uses, if known. Test on the full document length, not a short excerpt, since detection accuracy increases substantially with text length.
Conclusion
AI detection and AI humanization are competing technologies rooted in the same underlying science: the statistical properties of text generated by language models versus text written by humans. Detectors measure those properties. Humanizers adjust them. The quality difference between tools comes down to how precisely and comprehensively they address the actual measurements that detectors apply: perplexity at the word level, burstiness at the sentence level, and stylometric fingerprints at the document level. A tool that addresses all three with detector-guided optimization and continuous model updates is categorically different from one that merely rearranges sentences and substitutes synonyms. Understanding this distinction allows writers to make technically informed decisions about which tools to use, how to combine them with manual editing, and what realistic expectations for bypass performance look like in 2026.
Frequently Asked Questions
What are perplexity and burstiness, and why do they matter for AI detection?
Perplexity measures how predictable a text's word choices are given a language model. Language models generate text by selecting the statistically most probable next word at each step, producing systematically lower perplexity than human writing, which tends to make less predictable word choices. Burstiness measures how much sentence length and structure vary throughout a document. Human writing has naturally high burstiness, shifting between short and long sentences, simple and complex structures, and different grammatical forms. AI-generated text is low-bursty because each sentence is generated by the same statistical process, resulting in similar lengths and structures throughout. Together, the two properties form the primary statistical fingerprint that detection tools use to classify text as AI-generated or human-written.
How do AI detectors analyze text at a technical level?
AI detectors use a combination of statistical measurements and trained classifier models. At the statistical layer, they compute perplexity using a language model that estimates the probability of each word choice. At the classifier layer, they use transformer-based models such as RoBERTa, trained on thousands or millions of examples of both human and AI-generated writing. These classifiers learn to identify the statistical patterns that characterize AI writing across multiple dimensions simultaneously: perplexity, burstiness, lexical diversity, part-of-speech bigram frequencies, and discourse-level coherence markers. The classifier outputs a probability that combines evidence from all these dimensions into a single detection score.
Why do paraphrasers fail to bypass detection while humanizers succeed?
Paraphrasers change the surface appearance of text by substituting synonyms and rearranging clauses. These operations do not meaningfully change the statistical properties that detectors measure. Replacing one word with a synonym of similar formality and frequency leaves the perplexity of the surrounding sequence nearly unchanged. Rearranging sentence structure does not change the document's sentence length distribution. The text looks different to the eye but presents a nearly identical statistical profile to the detection classifier. True humanizers target the statistical properties directly: introducing vocabulary that is less statistically probable, restructuring sentence lengths across the document, and removing the model-specific stylistic patterns that stylometric classifiers detect. This is why paraphrasers reduce AI detection scores from 97 percent to around 60 percent, while quality humanizers can bring them down to below 10 percent.
What is stylometric analysis, and how does it apply to AI-generated text?
Stylometry is the quantitative study of writing style, originally developed for authorship attribution in forensic linguistics and literary studies. In AI detection, it applies to identifying the consistent stylistic patterns that characterize AI-generated text across linguistic dimensions beyond perplexity and burstiness: the type-token ratio (lexical diversity), the frequency of specific part-of-speech bigrams (grammatical patterns), the usage rate of function words like prepositions and conjunctions, and the discourse-level patterns governing how sentences connect to each other. Each major AI model has characteristic stylometric fingerprints: specific phrases that appear disproportionately frequently, preferred transition structures, and consistent distributions of grammatical categories. Advanced detection classifiers learn these fingerprints from training data and apply them alongside statistical measurements to improve detection accuracy.
How are AI humanizers and detectors evolving in 2026?
The relationship is an ongoing arms race. Detectors adapt by collecting outputs from popular humanizer tools, labeling them as AI-generated, and retraining their classifiers on that data. Turnitin announced in 2025 that it had developed specific detection for QuillBot-processed text. Humanizer tools respond by updating their models against the latest detector versions, diversifying their output patterns to avoid consistent signatures, and incorporating real-time detection feedback into their processing pipelines. The most sophisticated humanizers use detector-guided generation, selecting transformations that specifically reduce the target detector's confidence score at each position. The fundamental limits are set by the overlap between human and AI writing distributions: text that is adjusted to fall within the human writing statistical range is genuinely hard for any classifier to detect, because the classifiers are calibrated to that same distribution. Using an AI text transformer that operates at this statistical level, with continuous updates against current detector versions, represents the state of the art for reliable bypass performance.