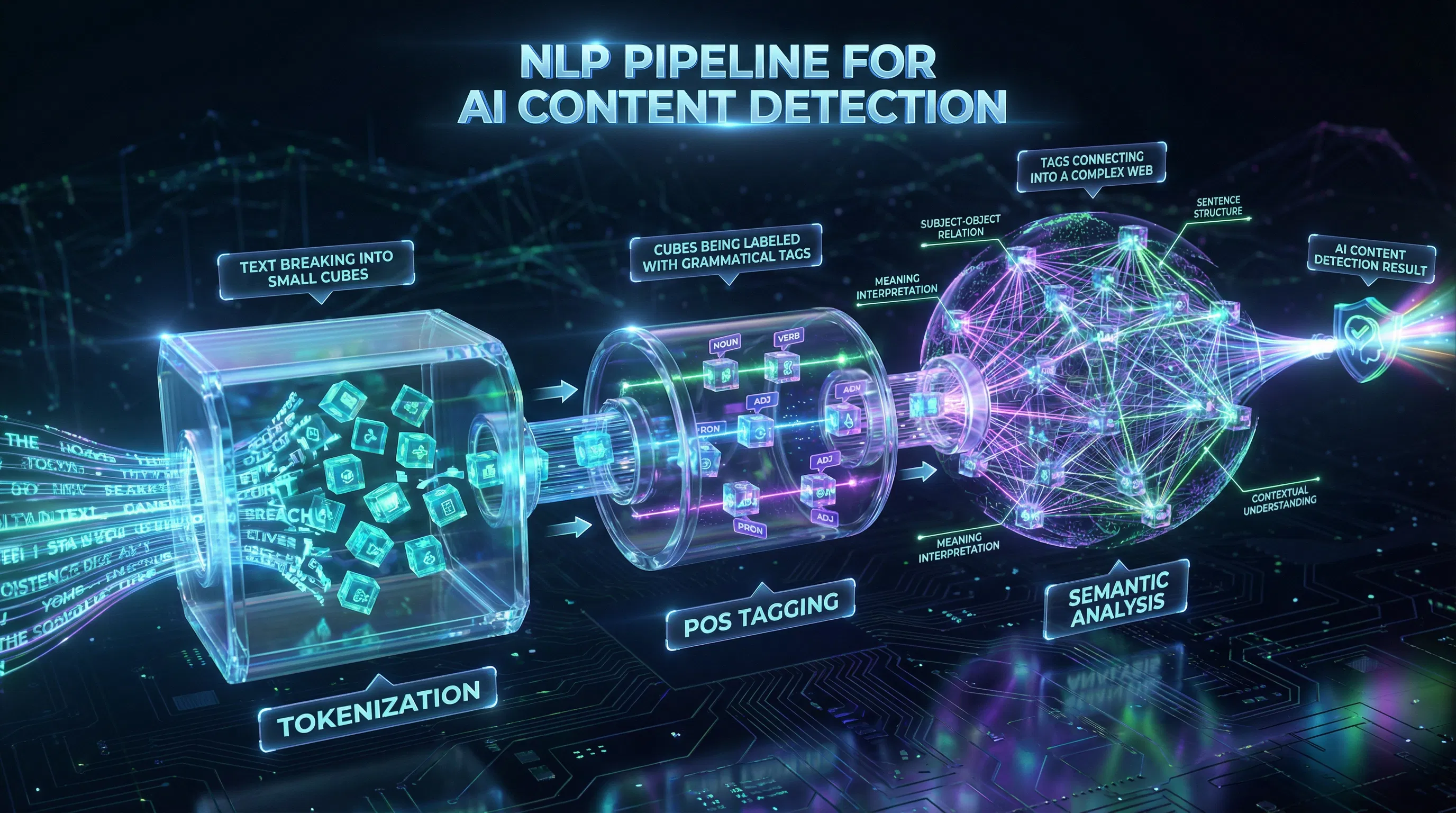
Ask most people how an AI detector actually works, and you will get a vague answer involving "machine learning" or "pattern recognition." The real answer is more specific: every detector depends on a pipeline of natural language processing steps that convert raw text into measurable numerical signals before any classification decision is made. Without those steps, there is nothing to classify. Perplexity scores, transformer embeddings, burstiness ratios, and stylometric features all come out of an NLP pipeline. The quality of that pipeline sets the accuracy ceiling of the entire detection system.
This dependency runs in both directions. NLP detection overview confirms that the most capable detection platforms in 2026 layer multiple NLP methods on top of each other precisely because no single approach covers all the ways AI-generated text differs from human writing. Every AI text humanizer built to make machine-generated content undetectable works by exploiting the same insight: if you know which NLP signals a detector measures, you can alter those signals in the output. Understanding the pipeline from the detection side tells you exactly why generic synonym substitution fails, why sentence restructuring works better, and why the best humanization tools address multiple NLP layers at once.
This guide covers the complete NLP pipeline from tokenization to transformer classification, explains where statistical and neural detection methods succeed and where they break down, and shows what it all means practically for writers, content teams, and organizations managing AI content at scale.
Key Takeaways
NLP is the foundation of every AI detector, not just one component. Every probability score and transformer embedding a detection system produces depends on a multi-stage NLP preprocessing pipeline. Get the pipeline wrong, and the classifier built on top of it cannot compensate.
Statistical NLP methods like perplexity scoring and burstiness analysis are fast but structurally fragile. Perplexity detection limits demonstrate that a single paraphrasing pass can defeat these metrics, and that famous human-authored texts like the Declaration of Independence regularly get flagged as AI-generated because language models were trained on them.
Fine-tuned transformer classifiers, especially RoBERTa, consistently outperform every statistical method. A 2025 study in Frontiers in Artificial Intelligence found that a custom RoBERTa model achieved 0.991 accuracy and an F1-score of 0.992 in AI text classification, with no statistical baseline coming close on the same dataset.
Model drift is the Achilles heel of neural NLP detectors. A classifier trained on GPT-3.5 output learns GPT-3.5-specific patterns. When GPT-4o, Claude 3.5, or DeepSeek V3 is released with different output signatures, accuracy falls until the model is retrained on the new data.
Ensemble architectures combining statistical screening with transformer classification represent the current performance ceiling. They achieve 94 to 99 percent accuracy on unedited AI text and maintain 75 to 88 percent on edited content, well above what either approach achieves on its own.
The NLP properties detectors measure are not permanent features of AI text. Token probability, burstiness, stylometric profiles, and embedding distances can all be shifted through revision. Tools that humanize AI content by targeting these NLP properties directly are fundamentally different from tools that just rephrase surface wording.
What Is Natural Language Processing? The Foundation of Detection
Natural language processing is the area of artificial intelligence that enables machines to work with human language. It converts unstructured text into structured numerical representations that downstream models can process. In practice, NLP covers a wide range of tasks: tokenization, part-of-speech tagging, syntactic parsing, semantic analysis, and named entity recognition. Each of these transforms raw text in a specific way, and each contributes distinct signals to a detection system.
Here is the key insight for understanding AI detection: NLP does not read text for meaning. It measures specific mathematical and linguistic properties of text, then uses those measurements to make classification decisions. The question a detector asks is not "does this sound human?" but rather "do the statistical patterns in this text match what we expect from a language model or from a human writer?" NLP use cases 2026 reports the NLP market grew to $34.83 billion in 2026, a 15.9 percent year-over-year increase, with content authenticity and AI detection applications driving a significant portion of that growth.
Core Principle: NLP does not read text for meaning. It measures token probability distributions, syntactic structure frequencies, and embedding space distances, then uses those measurements to classify authorship. Detection accuracy depends on which properties are measured, how accurately they are extracted, and how well the classifier generalizes across content types and LLM versions. |
This has a direct practical implication. Tools designed to bypass AI detectors do not work by fooling the detector's semantic understanding. They work by shifting the specific NLP-measurable properties that the detector uses. Surface-level wording changes alone are not enough, as they leave the underlying statistical fingerprint largely intact.

The NLP Pipeline: How Raw Text Becomes a Detection Signal
A detection system does not receive raw text and immediately make a classification. It first runs the text through a preprocessing pipeline. The quality of that pipeline determines the quality of the signal reaching the classifier. A weak preprocessing stage degrades even the most sophisticated downstream transformer model.
Technique 1: Tokenization and Breaking Text into Measurable Units
Tokenization is where every NLP pipeline begins. It is the process of splitting a continuous text string into discrete units called tokens. Those tokens can represent full words, subword segments, or individual characters, depending on the approach used. Modern transformer-based tokenizers use subword methods such as WordPiece or Byte-Pair Encoding, reducing vocabulary size by up to 40% while preserving semantic accuracy. NLP tokenization guide explains in detail how subword tokenizers handle rare vocabulary and domain-specific terms that word-level approaches struggle with, directly affecting how reliably perplexity scores reflect the text's true authorship signal.
For detection purposes, the token-level probability distribution matters most. This measures how likely each token is given everything that came before it. AI-generated text has systematically high token probability because the same model family produced it and would make similar word choices again. Platforms that reduce detection signals do so by restructuring token sequences until their probability distributions match those produced by human writers. Simply replacing synonyms does not accomplish this because the structural patterns remain.
Technique 2: Part-of-Speech Tagging and Syntactic Parsing
Once text is tokenized, part-of-speech tagging assigns a grammatical label to each token: noun, verb, adjective, adverb, preposition, and so on. Syntactic parsing then reconstructs sentence structure, identifying which words serve as subjects, objects, and modifiers. Together, these operations extract grammatical features that differ between AI and human writing in measurable ways.
Language models trained to produce coherent text tend to favour passive constructions, nominalization, and compound adjective phrases more than casual human writing does. POS bigram frequencies, which track how often pairs of grammatical categories co-occur, are among the most stable cross-domain stylometric features. They are less sensitive to the vocabulary domain than perplexity metrics, making them useful for detecting AI text across academic, journalistic, and marketing content without separate calibration for each genre.
Technique 3: Named Entity Recognition and Semantic Feature Extraction
Named entity recognition identifies specific entities in text, such as people, organizations, locations, dates, and numerical values. In AI detection, NER reveals how entities are referenced and contextualized. A language model tends to reference entities with formal consistency and encyclopedic precision. Human writers, by contrast, use entities more variably and contextually, drawing on personal familiarity rather than on recall of training data.
Semantic feature extraction goes further, computing numerical representations of what text segments mean rather than just what words they contain. This allows classifiers to measure semantic coherence and topical consistency across a document. AI-generated text tends to maintain an unusually uniform semantic density, advancing its topic at a steady pace without the natural digressions, qualifications, and tangents that characterize authentic expert writing. NLP classifiers can detect this uniformity even when surface-level perplexity has been corrected by editing.
Technique 4: Word Embeddings and Turning Words into Vectors
Word embeddings map tokens to dense vectors in a high-dimensional space where semantically related words cluster. Early approaches like Word2Vec and GloVe assigned a fixed vector to each word regardless of context. Transformer architectures improved on this significantly: they produce different embeddings for the same word depending on its full-sentence context, capturing how meaning shifts with surrounding language.
The embedding-space distance between a text's representation and the known distribution of human-authored content is the primary signal that fine-tuned transformer classifiers act on. Shift embedding-space position by combining sentence restructuring with vocabulary diversification across a document, not just paragraph by paragraph. Synonym substitution alone leaves the deeper embedding-space pattern intact because the structural relationships between ideas remain unchanged.
Statistical NLP Detection Methods
Core Principle: Statistical NLP detection methods require no labelled training data in their zero-shot forms. They compute mathematical properties of text using an existing language model and compare results against known AI and human output distributions. They are computationally cheap and partially effective on unedited AI text, but they measure surface-level properties that degrade quickly when text is edited. |
Perplexity Scoring
Perplexity is the exponentiated average negative log-likelihood of a text sequence. Think of it as a measure of how surprised a language model would be by the word choices in a given piece of writing. AI-generated text tends to produce low perplexity because the same class of model that wrote it would also predict similar word sequences. Human writing produces higher perplexity because people make less statistically predictable choices, reaching for personal idioms and unexpected phrasings that language models rarely generate by default.
The fundamental weakness of perplexity scoring is calibration dependency. The score you get depends heavily on which language model you use to compute it, what content domain the text comes from, and whether similar text appeared in the model's training data. Historical documents and widely reproduced academic writing score as AI-like, not because a machine wrote them, but because language models trained on that content predict it confidently. Any tool designed to beat perplexity checks must restructure sentences at a level that genuinely changes what the model predicts. Swapping synonyms does not move the needle.
Burstiness Analysis
Burstiness tracks how much perplexity varies across a document. High-burstiness text alternates between predictable and surprising passages, which is the natural rhythm of human writing. Some sentences are routine; others introduce a fresh observation or an unexpected turn of phrase. AI text tends to maintain consistently low perplexity throughout, never spiking because the model is always selecting statistically safe options. This produces a flat, low-burstiness profile that detection systems measure. Perplexity and burstiness serve as the statistical foundation of GPTZero's detection model, while acknowledging they share a common vulnerability: a single pass of sentence restructuring introduces enough rhythmic variation to defeat burstiness-based detectors.
N-gram Frequency Analysis
N-gram analysis tracks how often specific sequences of adjacent words appear. Language models tend to favor certain phrase-level constructions repeatedly because those sequences have high probability in their training data. N-gram detection captures this repetition at the phrase level rather than the individual token level, making it somewhat more resistant to synonym substitution than raw perplexity scoring. AI detection signals confirm that n-gram analysis works best as a supplementary signal within ensemble systems. Sentence-level restructuring, which changes clause order and recombines ideas, is sufficient to substantially disrupt n-gram profiles.
Stylometric Feature Classifiers
Stylometric classifiers take a broader approach than perplexity-based methods. Rather than measuring a single statistical property, they extract dozens of linguistic features: sentence length statistics, vocabulary diversity metrics, POS tag frequencies, readability scores, function word ratios, and punctuation entropy. These features feed into classical machine learning models like Support Vector Machines, Random Forests, and Logistic Regression. The result is a classifier that is faster and more interpretable than a transformer, and more robust across different content domains because it captures a richer feature set. AI vs. human text analysis found that AI-generated texts consistently show lower perplexity, more uniform sentence structure, and higher lexical repetition than human writing, though these gaps have narrowed as LLMs have become more sophisticated.
According to the NLP techniques guide from Label Your Data, POS bigram frequencies and sentence length variance rank among the highest-important stylometric features for distinguishing LLM-generated text. These properties are harder to fake than raw perplexity because they require genuine structural variety, not just word-level substitution.
Neural NLP Detection: Transformers in Practice
Statistical detection methods measure properties that researchers decided in advance were likely to differ between AI and human text. Neural approaches work differently. They learn from large labeled datasets of both types of writing and, through training, discover which multidimensional patterns best separate the two categories. Those patterns are not pre-specified; they emerge from data. Neural AI detection confirms that the most accurate neural detectors simultaneously analyze semantic coherence, stylistic consistency, syntactic structure, and information density. No single statistical metric replicates that combination.
BERT and RoBERTa: The Dominant Detection Architecture
BERT, which stands for Bidirectional Encoder Representations from Transformers, uses a masked language modeling objective to learn bidirectional contextual representations of text via self-attention. Each token is represented in the context of every other token in the sequence, not just the ones that came before it. For AI detection, a pre-trained BERT model gets a classification head added on top, then gets fine-tuned on labeled datasets of human and AI writing. The model learns to map full-sequence contextual representations to a binary output: human or AI.
RoBERTa improves on BERT in several concrete ways. It uses dynamic masking, which changes which tokens are masked across training epochs rather than fixing them upfront. It trains on larger batches with significantly more diverse data, over 160 GB compared to BERT's 16 GB. It also removes the next-sentence prediction objective, which was found to introduce noise without improving performance. The result is a base model that learns stronger contextual representations. When fine-tuned for detection, it consistently outperforms BERT. RoBERTa detection benchmark reports a custom RoBERTa classifier achieving 0.991 accuracy and an F1-score of 0.992, the highest benchmark performance for NLP-based AI text detection published in 2025.
The performance advantage of transformer classifiers over statistical methods comes from their ability to represent text in a high-dimensional embedding space, typically 768 dimensions for BERT-base and larger for RoBERTa variants, where AI generation patterns and human authorship separate geometrically. A perplexity score reduces all of that complexity to a single number. A transformer classifier retains a rich multidimensional representation of the entire sequence, capturing interactions among sentence structure, vocabulary distribution, discourse organization, and semantic coherence. Producing genuinely undetectable AI text requires addressing all structural dimensions, not just the surface ones that statistical detectors can detect.
DistilBERT and Lightweight Transformer Variants
DistilBERT compresses BERT to about 40 percent of its parameter count while retaining around 97 percent of its NLP performance. In the same 2025 Frontiers benchmark, DistilBERT achieved an F1-score of 0.988 and accuracy of 0.988, just below RoBERTa's 0.992 and 0.991. That is a very small accuracy gap at significantly lower computational cost, which is why DistilBERT tends to be the practical choice for the neural classification stage of production ensemble architectures where speed and throughput matter. NLP transformer algorithms note that domain-specific fine-tuning on academic, legal, or medical content can raise in-domain accuracy by 20 to 30 percent over general-purpose transformer baselines.
A separate Scientific Reports benchmark reinforces the transformer advantage: RoBERTa achieved 96.1% accuracy on a 20,000-sample balanced dataset covering diverse linguistic sources, outperforming BERT, DistilBERT, ALBERT, LSTM, and GRU on the same evaluation. That result comes from a study that applied post-hoc temperature scaling and threshold tuning, confirming that the accuracy advantage of fine-tuned transformers is robust even under calibration adjustments.
The NLP Techniques: A Reference Guide
The table below maps each core NLP technique to what it measures and how it contributes to AI content detection. Reading this table reveals the layered nature of detection: each method captures something the others miss, which is why the most capable platforms combine several of them rather than relying on any single approach.
NLP Technique | What It Measures | Detection Role |
Tokenization | Text segmented into measurable units | Enables token probability measurement; tokenizer quality affects perplexity accuracy directly |
POS Tagging | Grammatical category frequencies and bigrams | Feeds stylometric classifiers; one of the most stable cross-domain discriminative features |
Named Entity Recognition | Entity reference patterns and contextual usage | Reveals AI's characteristic entity consistency versus human variability |
Word Embeddings (static) | Semantic similarity in fixed vector space | Useful baseline signal; cannot capture how meaning shifts with context |
Contextual Embeddings | High-dimensional context-sensitive representation | Core signal for BERT and RoBERTa classifiers; captures what no single statistical metric can |
Perplexity Scoring | Token predictability under a language model | Fast initial screen; degrades quickly after editing; produces false positives on formal writing |
Burstiness Analysis | Variation in perplexity across document length | Adds a temporal dimension that raw perplexity misses; shares the same editing vulnerability |
N-gram Frequency | Contiguous word sequence repetition | More stable than perplexity under synonym substitution; fails against sentence restructuring |
Stylometric Features | Vocabulary diversity, function word ratios, sentence length variance | Cross-domain robustness; most effective as an ensemble component rather than standalone |
Ensemble (statistical + neural) | Combined multi-signal NLP output | Highest accuracy across all conditions; routes each case to the method best suited for it |
The practical takeaway is that effective content transformation has to address the full range of measurement categories, not just one or two. Using an AI content humanizer that targets the complete NLP signal profile is more reliable than patching individual metrics, because production detection platforms cross-validate multiple signals before committing to a classification.
Head-to-Head: NLP Detection Method Performance
The benchmark data on NLP-based AI detection is mature enough now to draw reliable conclusions. The figures below are drawn from the 2025 Frontiers in Artificial Intelligence study, the Scientific Reports RoBERTa benchmark, and real-world deployment evaluations. The AI detection guide 2026 confirms that leading detection platforms in 2026 achieve 90-99% accuracy on unedited AI-generated text, with ensemble systems performing best across all content types and editing conditions.
Detection Method | Pure AI Text Accuracy | Edited Text Accuracy |
Perplexity scoring (zero-shot) | 80 to 90% | 40 to 60% |
Burstiness + perplexity combined | 82 to 92% | 45 to 62% |
N-gram statistical classifier | 75 to 88% | 50 to 65% |
Stylometric feature classifier (SVM/RF) | 78 to 90% | 55 to 70% |
LSTM / BiLSTM (sequential neural) | 82 to 91% | 55 to 70% |
Fine-tuned BERT | 88 to 95% | 65 to 78% |
Fine-tuned RoBERTa | 92 to 99% | 70 to 83% |
DistilBERT (fine-tuned) | 90 to 98% | 68 to 81% |
Ensemble (statistical + transformer) | 94 to 99% | 75 to 88% |
A few caveats matter here. Accuracy figures vary based on which LLM produced the text, because a classifier trained on GPT-3.5 output will perform better on GPT-3.5 than on newer models it has not seen. The edited text figures reflect moderate paraphrasing, a single pass. Aggressively processed content achieves lower detection across all methods. Non-native English writers face systematically higher false positive rates under statistical methods, sometimes two to three times the baseline rate. Using a well-designed AI humanization tool is most critical precisely in the edited content scenario, where the accuracy gap between statistical and neural NLP detection is widest, and the stakes are highest.
Failure Modes: Where NLP Detection Breaks Down
Statistical NLP Failure Modes
Training data contamination. Perplexity assigns low scores to any text that appears frequently in LLM training data, regardless of who wrote it. Famous speeches, classic literature, and widely cited academic writing all score as AI-like, not because a machine produced them, but because the model has seen them so many times it predicts them confidently. This is a structural flaw in the method, not a tuning error.
Non-native English writing. Writers working in their second language tend to produce text with lower vocabulary diversity and more predictable grammatical constructions. These properties score as low-perplexity, AI-like text under statistical methods. How AI detectors work confirms this bias appears across multiple detection platforms and creates real consequences in academic integrity enforcement, where the students least likely to have used AI are sometimes the ones most likely to be flagged.
Domain mismatch. Perplexity thresholds calibrated on news articles will misclassify scientific papers because the two genres have systematically different baseline perplexity distributions. Statistical detectors that ignore domain context produce unreliable results whenever their calibration domain and the evaluated content domain do not match.
Adversarial editing. A single round of sentence restructuring is enough to push AI text outside the perplexity and burstiness thresholds of most statistical detectors. Platforms built specifically to evade AI detection by systematically altering these signatures reliably defeat statistical methods, which is why organizations relying solely on perplexity-based detection face a losing proposition in adversarial conditions.
Neural NLP Failure Modes
Model drift after new LLM releases. A transformer classifier trained on GPT-3.5 output learns GPT-3.5 patterns. When GPT-4o, Claude 3.5, or DeepSeek V3 enter the market with different output signatures, the classifier's accuracy on those new models degrades until it is retrained. AI detection trends 2026 confirms that platform update cadence is the single most consequential real-world accuracy factor, more important than whether the underlying method is statistical or neural.
Cross-domain generalization gaps. Classifiers trained on academic essays frequently underperform on creative writing. Classifiers trained on news content struggle with technical documentation. The research literature consistently documents accuracy drops of 15 to 25 percentage points when a high-performing model like RoBERTa gets evaluated on content types absent from its training data.
Explainability limitations. Transformer classifiers distribute their decisions across hundreds of attention heads and thousands of parameters. Without post-hoc tools like LIME or SHAP, there is no way to determine which NLP features drove a particular classification. This opacity complicates institutional review, academic integrity appeals, and regulatory audits where specific attribution is required.
Ensemble NLP Architectures: The 2026 State of the Art
The platforms achieving the highest detection accuracy in 2026 do not choose between statistical and neural methods. They combine them. The logic is straightforward: statistical methods are fast and cheap for high-confidence cases, while transformer classifiers are accurate and editing-resistant for borderline and ambiguous content. Running both in a layered pipeline exploits their complementary strengths without incurring the full computational cost of transformer classification per document.
Stage 1: Statistical NLP screening. Perplexity scoring, burstiness analysis, and n-gram frequency provide a fast initial assessment. Documents that score far outside the AI detection range are classified immediately. Everything in the uncertain middle proceeds to the next stage.
Stage 2: Transformer NLP classification. A fine-tuned RoBERTa or DistilBERT classifier performs deep, multi-dimensional analysis of borderline texts. The transformer's learned representations capture the editing-resistant structural patterns that statistical methods miss entirely.
Stage 3: Stylometric supplementation. Some production systems add stylometric NLP feature analysis as a third signal, especially for high-volume domains like academic writing and marketing copy, where LLM output has distinctive vocabulary signatures worth tracking separately.
Stage 4: Weighted confidence aggregation. Rather than treating each component as a binary vote, production systems combine probability scores from each NLP method using learned weights. The weights reflect the reliability of each method for the specific content type and document length being evaluated. This makes the ensemble more responsive to transformer outputs on edited content and to statistical signals in long, unedited text.
Content that needs to pass ensemble NLP detection requires an AI text transformer that addresses all NLP layers at once: statistical properties such as perplexity and burstiness, stylometric features such as sentence length variance and function word ratios, and transformer-level embedding patterns. A failure on any single layer is enough to trigger a positive classification in a multi-stage system.
What NLP-Powered Detection Means for Content Creators
Understanding how NLP detection works changes how you should think about AI content in a practical workflow. The pipeline is not a black box; it has predictable failure modes and an exploitable structure. The specific properties detectors measure, including token probability distributions, burstiness profiles, stylometric feature patterns, and transformer embedding distances, are not permanent features of AI-generated text. They can be shifted through the revision process.
What matters is the depth of that revision. A light synonym substitution pass does very little because it does not change the token probability structure, the grammatical distribution, or the embedding-space position of the text. Genuine sentence restructuring, introducing natural rhythm variation, adding first-person observations, and mixing sentence lengths are the edits that actually move the NLP metrics. That is why the most effective approach is to use a free AI humanizer that operates across the full range of NLP signals simultaneously, rather than patching one metric at a time and hoping the others do not betray you.
For organizations running detection platforms, the critical variable is not the underlying NLP methodology but the retraining schedule. A transformer classifier that does not get updated within days or weeks of a major LLM release degrades toward statistical-method performance levels on that new model's output. This makes update cadence more consequential than architecture choice when evaluating detection platform vendors.
Solution Section: Addressing NLP Detection in the AI Content Workflow
Transformer-based NLP classifiers fine-tuned on diverse datasets now achieve above 99% accuracy on unedited AI-generated text in controlled benchmarks. For content creators using AI writing tools, the question is no longer whether NLP can detect AI-generated content. It is whether the content workflow has the right tools to ensure output reads authentically before it reaches a detection system.
Understanding What NLP Detectors Target
Every NLP-based detection system measures the statistical distance between the text being evaluated and the known output distributions of large language models. This is true whether the detector uses perplexity scoring or a fine-tuned transformer. Both approaches are measuring distributional conformity, not meaning. The practical implication is that altering the statistical properties of the text, not its semantic content, is what matters for detection. The more substantively AI-generated content is restructured and given an authentic voice, the more its NLP profile shifts toward the human distribution.
Unlimited Access to NLP-Informed Content Processing
One underappreciated barrier to maintaining NLP detection compliance across a high-volume content workflow is scale. Many transformation platforms impose per-word costs or subscription tiers that make it impractical to run every piece of content through the process consistently. The result is selective processing, which creates uneven quality across a content library. Humanize AI writing provides free, unlimited AI text transformation so that teams can process everything they publish, not just the content they are most worried about.
Flexibility Across NLP Content Contexts
NLP detection performance varies across content domains because each domain has different baseline statistical distributions. Academic writing, marketing copy, technical documentation, and creative content each have different expected perplexity ranges, typical stylometric profiles, and characteristic transformer embedding positions. A transformation tool calibrated to one domain may produce suboptimal results in another. Effective platforms allow adjustment of output characteristics to match the NLP property distribution expected for the specific content type being produced.
Compliance Integration: From Detection Risk to Resolved Content
For organizations in education, publishing, healthcare, or financial services, NLP-based AI detection is increasingly a governance matter. Detection results that may be reviewed in institutional or regulatory contexts require workflows that demonstrate how content was verified and revised. An effective compliance workflow integrates detection testing, transformation, and re-testing into a traceable process that produces a clear audit trail: the document was submitted to NLP detection analysis, the identified risks were addressed, and the revised content passed review.
Conclusion
NLP is not one ingredient among several in AI content detection. It is the foundation the entire system builds on, from the tokenization pipeline that makes probability measurement possible to the transformer classifiers that capture patterns no statistical metric can express. Understanding which NLP properties detection systems measure, and why those properties behave as they do under editing, is a prerequisite for reliable AI detection bypass. The gap between content that gets flagged and content that passes is the gap between surface-level cosmetic changes and genuine NLP-level transformation.
Frequently Asked Questions
How does NLP work in AI content detection?
NLP-based AI content detection works through a sequential pipeline that converts raw text into structured numerical signals before any classification decision is made. First, tokenization breaks the text into measurable units. Then, part-of-speech tagging, semantic feature extraction, and word embedding produce the linguistic representations that detection models analyze. Statistical methods measure token probability distributions directly from those representations. Neural classifiers use transformer architectures to generate high-dimensional contextual embeddings that capture complex structural patterns. Tools built to beat AI detectors work by targeting these pipeline outputs at the signal level, not by rewriting surface wording that the classifier never directly measures.
What is the role of tokenization in detecting AI-generated text?
Tokenization is the step that enables all other detection operations. Breaking text into discrete units creates the token-level probability distributions that perplexity scoring and log-likelihood analysis depend on. The choice of tokenization method matters: subword approaches like WordPiece and Byte-Pair Encoding handle rare vocabulary and domain-specific terms that word-level methods struggle with, thereby improving the accuracy with which perplexity scores reflect the true authorship signal rather than an artifact of vocabulary mismatch.
Why do perplexity and burstiness fail as standalone AI detection signals?
They fail for two structural reasons. First, they depend on calibration: absolute perplexity is a function of which language model computes it and which content domain the text comes from, not just whether a human or AI wrote it. Famous human-authored texts and formal academic writing regularly score as AI-like because language models were trained on them. Second, both metrics measure surface-level properties that change after light editing. A single synonym substitution pass moves perplexity scores, and sentence restructuring artificially raises burstiness without changing anything about the text's actual authorship.
How do transformer models like BERT and RoBERTa detect AI-written content?
BERT and RoBERTa learn to detect AI-generated content by training on large, labeled datasets of human and AI-generated text, discovering the multidimensional NLP patterns that distinguish the two categories. These models produce contextual embeddings, high-dimensional vector representations in which the structural regularities of AI-generated text appear as geometric distances from the human text distribution. A classification head trained on top of those embeddings learns to map those distances to a binary output. RoBERTa consistently outperforms BERT on this task because its pre-training approach, with dynamic masking, larger batches, and more diverse training data, produces embeddings that are more sensitive to subtle NLP differences between AI and human writing.
What NLP techniques give the most accurate AI detection results in 2026?
Ensemble architectures combining statistical screening with fine-tuned transformer classification produce the most accurate results. Statistical methods like perplexity scoring handle high-confidence cases quickly and cheaply. Fine-tuned RoBERTa or DistilBERT classifiers handle borderline and edited content with accuracy that no statistical method matches. These ensemble systems achieve 94 to 99 percent accuracy on unedited AI text and 75 to 88 percent on edited content. Beyond architecture, the most consequential variable is how quickly the platform retrains after major LLM releases. A classifier updated within days of a new model's release maintains its advantage. One that waits months degrades toward statistical-method performance levels on the newest outputs.